HTML Technical Cheat Sheet
1 HTTP Response Status Codes
Some common Response Codes
| Stat | Status Message | Meaning | <c> | |
|---|---|---|---|---|
| Code | Category | |||
| 100 | 100-199 | Informational responses | Info | |
| 200 | OK | O | All good | Success |
| 201 | Created | C | New resource created | |
| 202 | Accepted | A | Accepted | |
| 203 | Info (N.auth) 1q | I | Non authoritative info | |
| 204 | No content | NC | No content | |
| 301 | Moved permanently | M | all future requests should to direct to new URL | Redirects |
| 302 | is Found here | F | requested resource temporarily resides here | |
| 304 | Not modified | M | good for reducing overhead, says you have it. | |
| 400 | Bad request | B | Request itself was invalid, i.e. bad | |
| 401 | Unauthorized | U | Authentication missing or invalid | Client |
| 403 | Forbidden | F | Authenticated user not authorized for resource | Errors |
| 404 | Not Found | F | Resource not found | |
| 405 | Not Allowed | A | Method exists but you are not allowed |
|
| 406 | Not Accepted | A | Requested MIME type does not match type I can offer | |
| 407 | Proxy Auth req'd | P | Similar to 401, but auth done by proxy | |
| 408 | Request Timeout | T | Server shutdown the request due to time expiring | |
| 409 | Conflict | C | Request conflicts with current state | |
| 410 | Gone | G | The requested resource is no longer available | |
| 413 | Request too large | L | Large | |
| 415 | Unsupported Media | M | request did not specify a Media type that is | |
| supported | ||||
422 |
Unprocessable |
U | Request was correct and understood, but | |
| server unable to process it. | ||||
423 |
Locked |
L | temporarily unavailble, locked, see "retry-after" | |
428 |
Precondition req. |
P | Files cannot be scanned for malware, need to | |
| be forced downloaded | ||||
429 |
Too many requests |
T | HTTP rate limiting. An API constraint. | |
| 500 | Internal Server | I | Something wrong with the server | Server |
| error | Errors | |||
| 502 | Bad Gateway | G | Server got an invalid response from upstream gw | |
503 |
Unavailable |
U | Server is overloaded with requests. try again |
|
| 504 | Gateway Timeout | T | upstream server failed to respond on time |
My mnemonic to remember some common Response Codes. "Oh crap! Andy is not captain. Mother f***in ginger!! Brave under fire for almost always protecting toronot's child gangs. Montreal's uber laws problem required too. I but."
| Stat | Status Message | mnemonic | ||
|---|---|---|---|---|
| Code | ||||
| 100 | 100-199 | Inform | 100 | |
| 200 | OK |
O | ok | 200 |
| 201 | Created | C | charles | 201 |
| 202 | Accepted | A | Atlas | 202 |
| 203 | Info (N.auth) |
I | is | 203 |
| 204 | No content |
C | no content | 204 |
| 301 | Moved permanently | M | My | 301 |
| 302 | Found here | F | first | 302 |
| 304 | Not modified | N | monkey | 304 |
| 400 | Bad request | B | Brave | 400 |
| 401 | Unauthorized | U | under | 401 |
| . | . | . | 402 | |
| 403 | Forbidden |
F | fire | 403 |
| 404 | Not Found |
F | for | 404 |
| 405 | Not Allowed |
A | almost | 405 |
| 406 | Not Acceptable |
A | always | 406 |
| 407 | Proxy Auth req'd | P | protecting | 407 |
| 408 | Request Timeout | T | Toronto's | 408 |
| 409 | Conflict | C | child | 409 |
| 410 | Gone | G | gangs. | 410 |
| 413 | Request too large | L | Large | 413 |
| 415 | Unsupported Media | M | Montreal's | 415 |
| --- | ||||
422 |
Unprocessable |
U | uber | 422 |
423 |
Locked |
L | law | 423 |
| --- | --- | |||
428 |
Precondition req. |
P | problem | 428 |
429 |
Too many requests |
T | too many requests | 429 |
| 500 | Internal Srvr err | I | IGUT | 500 |
| --- | 501 | |||
| 502 | Bad Gateway | G | IGUT | 502 |
503 |
Unavailable |
U | IGUT | 503 |
| 504 | Gateway Timeout | T | IGUT | 504 |
OK Created Accepted info No Content OK Charles Atlas is No Content 200 201 202 203 204
My first monkey 301 302 303
Brave under fire for almost always protecting toronot's child gangs. 401 402 403 404 405 406 407 408 409 410
Large Montreal's uber law problem too many requests 413 415 422 423 428 429
I - g u t 500 - 502 503 504
2 HTTP is client:server
HTTP is an application layer protocol based on a client/server model where
the browser is the web client, and the web server is the server. THe client
sends http requests and the server replies back with http responses. These
requests and responses are messages.
3 HTTP is stateless
The server does not retain any client information, and each request can be
understood in isolation. To get some stateful behaviours, you can use headers.
It is also media independent, i.e. any client that understands http can send
requests to a server, and get responses.
3.1 HTTP messages
- encoded in ASCII
- in HTTP/1.1 messages were openly sent across a tcp connection.
- in HTTP/2 the once human readable messages are broken up into HTTP frames
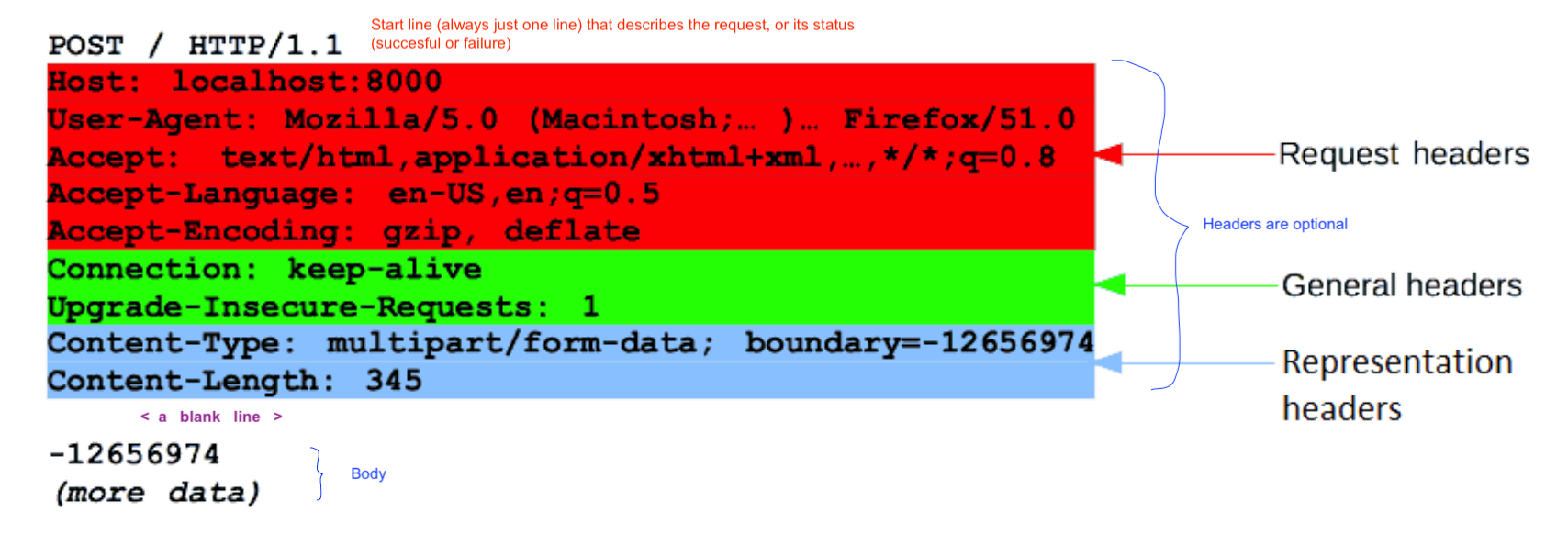
4 HTTP Request Structure:
From developer.mozilla.org :
HTTP requests, and responses, share similar structure and are composed of:
- A
start-linedescribing the requests to be implemented, or its status of whether successful or a failure. This start-line is always a single line.. - An
optionalset ofHTTP headersspecifying the request, or describing the body included in the message. - A
blank lineindicating all meta-information for the request has been sent. - An
optionalbodycontaining data associated with the request (like content of an HTML form), or the document associated with a response. Thepresenceof the bodyand itssizeis specified by the start-line and HTTP headers.
4.1 Start-line
Composed of three elements:
GET zintis.net HTTP/1.1
4.1.1 a) HTTP method that describes the action to be performed
An HTTP method can be a verb
GETPUTPOSTPATCHor an HTTPmethodcan be anounHEADOPTIONS
4.1.2 b) ~Resource
A request target~, usually a URL, or the absolute path of the protocol,
port, and domain are usually characterized by the request context
4.1.3 c) HTTP (protocol) Version
Will be presently either HTTP/1.1 or HTTP/2.0
4.1.4 Examples of Request Start lines
POST / HTTP/1.1 GET zintis.net HTTP/1.1 PUT /customers HTTP/1.1 HEAD OPTIONS
4.1.5 Examples of Response Start lines.
HTTP/1.1 403 Forbidden
4.2 HTTP Headers
Optional
a case-insensitive string followed by a colon (':') and a value whose
structure depends upon the header. The whole header, including the value,
consist of one single line, which can be quite long.
For example:
- content-type: application/json
- Authorization: Basic BDz6bmV0uXqlcjpDaXkjTzEQMyE=
- Accept: application/json # this is the MIME type you will accept
- Accept-Language: en-us, en-GB;q-0.9, lv-eu-0.9, fr-eu-0.2
- User-Agent: Mozilla/4.0
- Connection: Keep-Alive
The q=0.9 is the quality factor rating. between 0 and 1, 1 being most
preffered.
4.2.1 General Headers
- not specific to request or response headers
- info on message itself, and how to process it
Cache-Control:Connection:Date:
4.2.2 Request Headers
- carry info about the resource to be fetched
- carry info about the client
Accept-(*):define the preferred responseAuthorization:often a Base64-encoded authentication string, username and password. Can use:echo -n "admin:Cisco123!" | base64on MacOSx or Linux to generate the base 64 string.Cookie:a list of key-value pairs with more info about session, user, browsing activity, shopping cart, etcHost:specify the host and port # of the resource being requested. this is requiredUser-Agent:info about user agent originating the request.
4.2.3 Response Headers
- hold info about the response and the server providing it.
Age:amount of time since the response was generated.Location:redirect the client to another locationServer:Contains the information about the software on the server handling this requestSet-Cookie:Used to send cookies from server to client. It's a list of key-value pairs
4.2.4 Entity Headers
contain information about the resposne body
Allow:a list of supported methods idenified by the requested resourceContent-Type:the media type of the body, MIME type.Content-Language:describes the language for the enclosed bodyContent-Length:the size of bodyContent-Location:the resource location for the entity accessible elsewhereExpires:datetime after which content is considered staleLast-Modified:datetime which origin server thinks the content was last modified.
4.2.5 Headers and Body together
The start-line and HTTP headers of the HTTP message are collectively known as
the head of the requests, whereas its payload is known as the body.
4.3 A blank line
Always seperates the headers (one line) and the body (one or many lines)
4.4 Body
Final part is the body. Usually get, post, head, delete requests do NOT have a body, because they are just fetching resources. But if a body is there it will have either Content-type or Content-length matching file. or a multi part resource body such as HTML Forms, where each part contains different information.
5 Review of base64 encoding
Where: String composed of "Basic”, followed by a space, followed by the
Base64 encoding of “username:password”, NOT including the quotes. For example
Basic YWRtaW46TWFnbGV2MTIz, where YWRtaW46TWFnbGV2MTIz is the Base 64
encoding.
To get the credentials into a Base64 encoding you can send username:password through any Base54 encoding site, such as base64encode.org or in terminal:
echo -n "username:password" | base64-n needed to remove the \n from echo string.
For example, echo -n "devnet:Cisco123" | base64 gets me ZGV2bmV0OkNpc2NvMTIzC
Reverse: echo "ZGV2bmV0OkNpc2NvMTIzC" | base64 -d gets me devnet:Cisco123
Note: If you want the password to contain special characters that
are normally interpretted by the shell, you must \ escape the character first
as in: echo -n "devnet:Cisco123\!" | base64 which is ZGV2bmV0OkNpc2NvMTIzXCEK=
The = or == are padding characters at the end of the string, if it does not
land on proper boundary that base64 is looking for.
6 HTTP Response Structure:
From developer.mozilla.org : A response has three parts:
Status line(similar to the start line)HeadersBody
6.1 Status line
The status line of an HTTP response, called the status line, contains the following three elements:
6.1.1 1) HTTP (protocol) version,
Usually HTTP/1.1.
6.1.2 2) Response (reason) code
Indicating success or failure of the request. a.k.a. Status code. eg:
- 200,
- 404,
- 302
6.1.3 3) Respone code text
A.k.a. status text. A brief, purely informational, textual description of the
status code to help a human understand the HTTP message. Like Not Found
A typical status line looks like:
HTTP/1.1 404 Not FoundHTTP/1.1 200 OK
6.2 Response Headers
- see section above.
6.3 Blank Line
Always seperates the headers (one line) and the body (one or many lines)
6.4 Body
- same as in
HTTP requests, but typically most of what the user is asking for is returned in the body of an HTTP response.
Typically of three categories
Single-resource bodiesconsisting of a single file of known length, defined by the two headers:Content-TypeandContent-LengthSingle-resource bodiesconsisting of a single file of unknown length, encoded by chunks withTransfer-Encodingset tochunkedMultiple-resource bodiesconsisting of a multipart body, each containing a different section of information, but these are rare.
7 URL
URLs identify resources targetted by the request.
https://zintis.net:9090/contact?action=show#page=4
https://zintis.net:9090/contact/index.html?action=show?key2=value2#page=4
They are composed of
- a scheme
https:// - a host
zintis.net - a port
:9090 - a path
/contact/index.html - a query string
?action=show?key2=value2 - a anchor
#page=4

7.1 URI
identifies the resrouce ./org-graphics/url.png~
7.2 URL
tells you where to locate or find it zintis.net
7.3 URN
uses a URN scheme: urn:people:names:alice.
7.4 curl
curl https://deckofcardsapi.com/api/deck/dec40fca2d5/draw/?count=3 | python -m json.tool
The uri is the usual scheme://host/path/?query
The full uri is:
userinfo host port
┌───────┴───────┐ ┌────┴─────┐ ┌┴┐
http://john.doe:password@www.acme.com:123/forum/questions/?tag=networking&order=newest#top
└─┬─┘ └───────────┬─────────────────────┘└─┬─────────────┘└────────┬──────────────────┘└┬─┘
scheme authority path query fragment
curl uses:
-Xfollowed by a request verb,GET, PUT,POST, PATCH, or DELETEor-Hfollowed by a header such as a token to send with the requests.Device:~# curl -i -k -X "POST" "https://10.85.116.30:443/restconf/data/Cisco-IOS-XE-native:native/logging/monitor" \ > -H 'Content-Type: application/yang-data+json' \ > -H 'Accept: application/yang-data+json' \ > -u 'admin:admin' \ > -d $'{ > "severity": "alerts" > }'
- -X
what follows is a request verb:
GET, PUT, POST, PATCH, DELETE - -K <file>
–config <file> Specify a text file from which to read curl arguments
- -H <header>
–header Either a file of headers or the actual headers
- -i
–include Include the HTTP resposne headers in the output
- -v
–verbose Let's you see request headers.
- -u
Specify user and password
-u 'admin:admin' - -d
–data Sends the specified data in a POST request to the server If the data starts with a @, then what follows is a filename that has the data.
- example
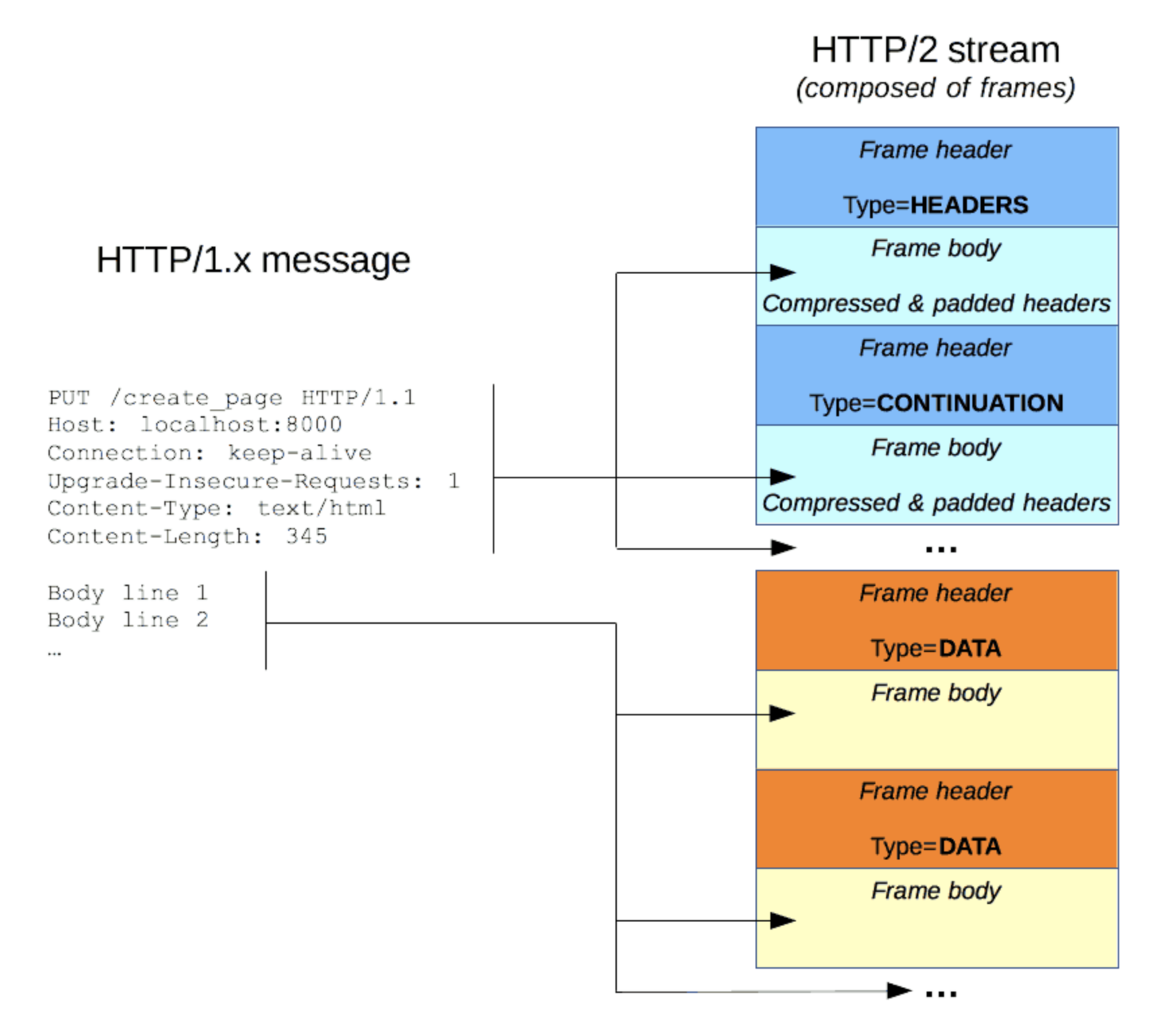
8 HTTP/2
HTTP/1.x messages have a few drawbacks for performance:
- Headers, unlike bodies, are
uncompressed. - Headers are often very similar from one message to the next one, yet still
repeatedacross connections. No multiplexingcan be done. Several connections need opening on the same server: and warm TCP connections are more efficient than cold ones.
HTTP/2 introduces an extra step: it divides HTTP/1.x messages into frames
which are embedded in a stream. Data and header frames are separated, this
allows header compression. Several streams can be combined together, a
process called multiplexing, allowing more efficient use of underlying
TCP connections.
As far as the REST APIs, no changes need to be made when using http1.1 vs
http2.
9 HTTP Methods
An HTTP method can be a verb
GETPUTPOSTor an HTTPmethodcan be anounHEADOPTIONS
These are what you want done, i.e. the action to perform. Some methods are
read-only, or safe, or idempotent. Idempotent reqests can be run many times
and the result is the same, with no extra resource allocation on the server.
Some methods are non-idempotent, such as posting a comment on a blog. If you send the post 3 times, you will see three of the same comments posted.
| HTTP | Idempotent | Function |
|---|---|---|
| GET | Yes | Requests a specific resource |
| POST | No | Submits an entity to the specified resource |
| DELETE | Yes | Deletes the specified resource. Deleting twice |
| should not cause any side-effects | ||
| PUT | No | Replaces all current representations of the target |
| resources with this payload | ||
| HEAD | Yes | Same as a GET, but only asks for headers, no body |
| in the response. | ||
| PATCH | No | Applies partial mods to a resource, when a PUT |
| would be too much at once. |
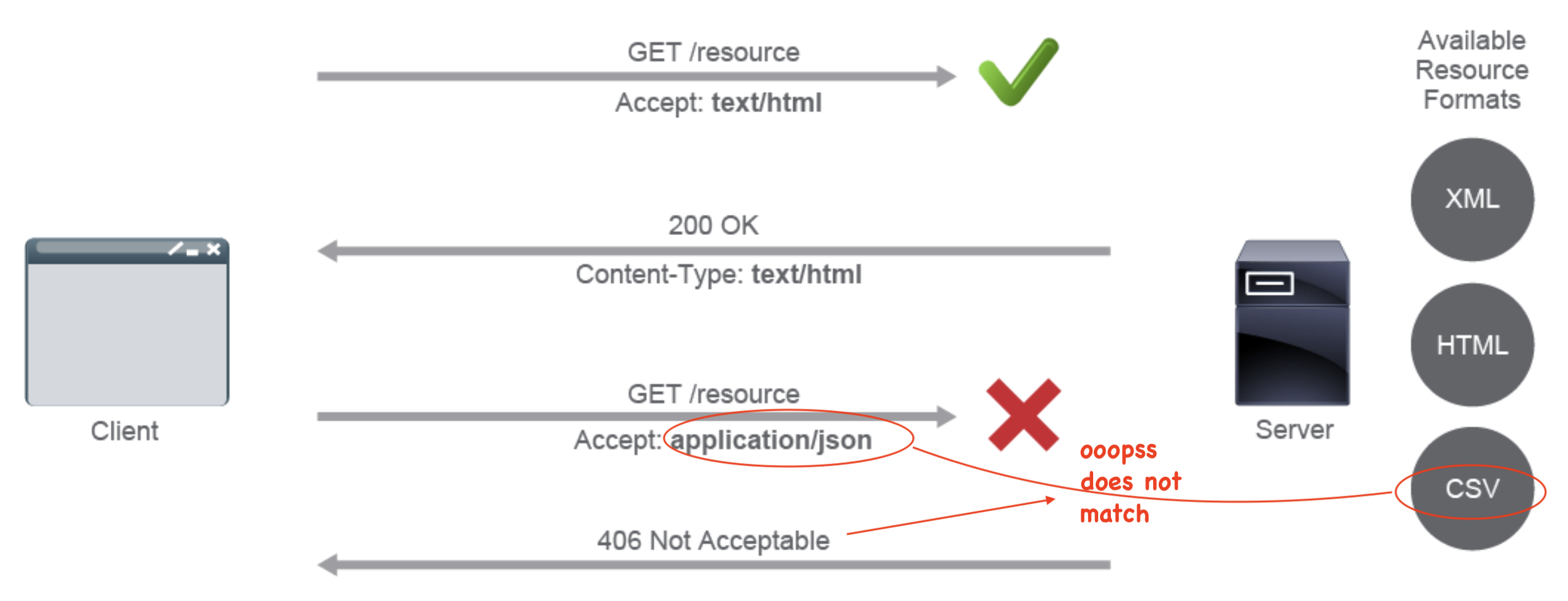
10 HTTP Content Negotiation
Because there are so many different form factors in web clients, web server need to be able to negotiate with the clients how to present the content of their responses.
The content returned is determined by various types of request headers of the
Accept: form. These headers are only the preferred resource representations
If the server cannot meet the format request it responds with a 406 Content
Not Acceptable, i.e. no content conforms to criteria supplied. In my
mnemonic, that is:
Brave under fire for almost always protecting toronot's child gangs. 401 402 403 404 405 406 407 408 409 410 Montreal's uber laws problem too-many-requests 415 422 423 428 429
Timeout Conflict Gone
Bad unauthorized forbidden not-found not-Allowed not-Accepted Proxy Timeout Conflict bad-Gateway
401 402 403 404 405 406 407 408 409 410
Media Unprocessable Locked Precondition Too-many-requests
415 422 423 428 429
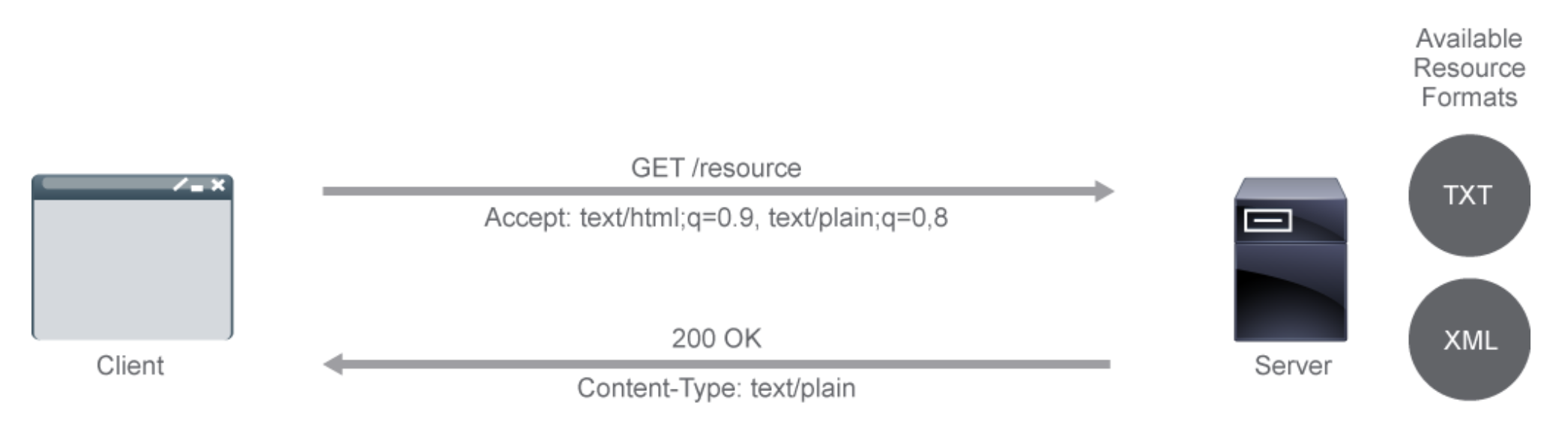
10.0.1 Quality Factor WeightingAll these headers support quality-factor weighting.
In negotiating between acceptable presentation formats, the clients can
give a preference for one format over another. This is done through the
q-factor ranging from 0 (unacceptable) to 1 (most preferred). 1 is default.
The q-factor is included (optionally) in the Accept- headers with a
- semicolon
- q=0.5
For example Accept-Language: en-US;q=0.8, en-GB;q=1, en-IN;q=0.8, *;q=0.7
10.1 Accept: Mime-Types Headers
From Cisco Devnet: A media type represents a general category and the
subtype, which identifies the exact kind of data. A general type can be
either discrete (representing a single resource) or multipart, where a
resource is broken into pieces, often using several different media types
(for example, multipart/form-data).
These are the common Mime-Types you may see in REST APIs:
Application-AudioImageTextVideo
10.2 Accept-Charset: Headers
UTF-8orISO 8859-1Sets the preferred character sets, such as UTF-8 or ISO 8859-1. It is important when displaying resources in languages that include special characters.
10.3 Accept-Datetime:
Requests a previous version of the resource, denoted by the point in time with datetime. The value must always be older than the current datetime.
10.4 Accept-Encoding:
Sets the preferred encoding type for the content.
10.5 Accept-Language:
The preferred natural language. Useful for various localizations.
10.6 Quality-factor weighting. (0 < x <= 1)
All these headers support quality-factor weighting.
It allows the user or user agent to indicate the relative degree of
preference for that media range, using the q-value scale from 0 to 1. The
default value is q=1.
A request header that prefers U.S. English over British English but still prefers British English over Indian English would look like this, with 1 being the default, so if it is omitted, it is 1: These are identical
Accept-Language: en-US, en-GB;q=0.9, en-IN;q=0.8, *;q=0.7Accept-Language: en-US;=1.0, en-GB;q=0.9, en-IN;q=0.8, *;q=0.7
10.7 Content Negotiation Example
From Cisco Devnet: These two requests and their corresponding response are for the same data but use different content types.
Request Header:
GET http://www.example.com/api/menu Accept: application/json Accept-Language: en-GB
Response:
{ "menu": { "name": "crisps" } }
Request Header:
GET http://www.example.com/api/menu Accept: application/xml Accept-Language: en-US
Response:
<?xml version="1.0" encoding="UTF-8"?> <menu> <name>chips</name> </menu>
11 Server vs Agent driven Content Negotiation
HTTP provides you with several different content negotiation mechanisms. Generally, they can be split into two groups:
server-drivennegotiation (proactive)agent-drivennegotiation (reactive).
11.1 Server-driven negotiation:
(i.e. the server makes the decision)
clientsubmits a request to a server.- The
clientinforms the server which media types it understands- ("
Accept" headerandquality-factorweighting).
- ("
- The
serverthen supplies the version of the resource that best fits the request. Often, redirection is used to point the client to the correct resource.
11.2 Agent-driven Negotiation (a.k.a. client-driven negotiation)
(scales much better than server-driven negotiation) i.e. the server does NOT decide, but merely dumps a list of multiple choices of supported types. the client decides based on this list.
- an user agent (or any other client) submits a request to a server. The agent resides on the client side, i.e. browser
- The
serverresponds and provides theagent with available representationson theserverand their locations, usually with a "300 Multiple Choices" response that depends on the application implementation. - The
useragent then makesanother requestto the desired URL for theactual resource.

12 RPC Style APIs
There is REST APIs and RPC APIs and others less common. RPC are more insterested in getting the server to do something, rather than just retrieving information from it. i.e. "Execute this command"
Server side handles the errors.
| Stengths | Weaknesses | |
|---|---|---|
| REST | ||
| APIs | ||
| RPC | ||
| APIs |
Remote Procedure Calls APIs "call" a remote procedure on a different address
space. i.e. different computer or different network. This is a style of
building an API. THere are several common / practicl implementations:
These are more complex, and less flexible. For example to find if your request was processed correctly, you would have to parse the response from these calls. Contrast that with REST, that gives you a status code on every response. 200 OK means you are good to go, and you do not even need to parse the whole response. That is because, while SOAP and XML-RPC use http, they do so only as a transport, and the body of the messages is still its own protocol in xml.
While REST natively uses HTTP methods as well as HTTP for trasport.
Client sends a call to the server, with parameters.
Server replies with a message.
Clients can send as many RPC "calls" as needed. They are handled concurrently, so can be run asynchronously.
Because the network is involved with remote calls, you need to manage:
error handlingandprocedure errorsshould be handled on the remote server, then sent back to client.Global variablesand theirside effectson remote server are hidden to a client. (client has no access to server address space)performancetakes a hit on slow networks, plus there is transport overhead.
12.1 SOAP
Simple Object Access Protocol (on WSDL)
SOAP has been around since ?? and is often the underlying layer to some of the
more complex web services. (based on WSDL, Web Services Description Lanaguage)
WSDL is an interface for describing functionalities offered by web services,
which in turn make discover and integration with a remote web service very
straightforward.
SOAP is extensible. Features can be added without major updates to the implementation. Security (WS-Security or WSS) and WS-Addressing can be added to SOAP.
SOAP is neutral. SOAP is not protocol specific and is able to operate over several different transport protocols, such as HTTP, TCP, Simple Mail Transfer Protocol (SMTP), and so on.
SOAP is independent It supports any programming model (object-oriented, functional, imperative, and so on), platform, and language.
The SOAP spec defines the messaging framework in four parts
Envelope- Ids the XML document as a SOAP message. IsrequiredHeader- contains theSOAPheader information.Body- contains the remotecall,parameters, andresponseinformation.Fault- Provides information about any errors that occurred..
Example of a SOAP request:
POST /Quotation HTTP/1.0 Host: www.xyz.org Content-Type: text/xml; charset = utf-8 Content-Length: nnn <?xml version = "1.0"?> <SOAP-ENV:Envelope xmlns:SOAP-ENV = "http://www.w3.org/2001/12/soap-envelope" SOAP-ENV:encodingStyle = "http://www.w3.org/2001/12/soap-encoding"> <SOAP-ENV:Body xmlns:m = "http://www.xyz.org/quotations"> <m:GetQuotation> <m:QuotationsName>MiscroSoft</m:QuotationsName> </m:GetQuotation> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
Example of a SOAP request:
POST /Quotation HTTP/1.0 Host: www.xyz.org Content-Type: text/xml; charset = utf-8 Content-Length: nnn <?xml version = "1.0"?> <SOAP-ENV:Envelope xmlns:SOAP-ENV = "http://www.w3.org/2001/12/soap-envelope" SOAP-ENV:encodingStyle = "http://www.w3.org/2001/12/soap-encoding"> <SOAP-ENV:Body xmlns:m = "http://www.xyz.org/quotations"> <m:GetQuotation> <m:QuotationsName>MiscroSoft</m:QuotationsName> </m:GetQuotation> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
12.2 JSON-RPC
Simple, light-weight RPC protocol, encoded in JSON with just these few
data types:
stringintegerbooleannull
And just these commands:
paramsmethodid
It supports notifications like sending data to the server that does not
require a response. (useful for asynchronous updates and batch requests
that have multiple requests inside one request body)
A standard protocol for procedure call support (lightweight) can run over HTTP, but is NOT a REST API. defines the REQUEST and RESONSE format only for sending communication from one device to another. Can send CLI commands.
Watch the transaction ids (to repond to the correct request)
Request:
[
{
"jsonrpc": "2.0",
"method": "cli",
"params": {
"cmd": "show ip int brief vrf management",
"version": 1
},
"id": 1
}
]
This example had "method": "cli" which returns nice structured
data, jsonrpc data. This format is the easiest way for
programs to consume it.
The other option is "cli-ascii" which would return a more
traditional, human readable cli output, as one raw string. Some
older "screen scraping" scripts may want this type of output.
Response
{
"jsonrpc": "2.0",
"result": {
"body": {
"TABLE_intf": {
"ROW_intf": {
"intf-name": "mgmt0",
"prefix": "10.10.20.58",
"ip-disabled": "FALSE",
"iod": 2,
"proto-state": "up",
"link-state": "up",
"admin-state": "up"
}
}
}
}
"id": 1
}
See also JSON-RPC :
12.3 XML-RPC
Similar to SOAP, however less structured, with fewer constraints. It
supports the basic types plus more complex types like Base64, array,
datetime, struct. It also support basic http authentication
2019 XML-RPC "reboot" http://reboot.xmlrpc.com is a re-issue, this time supporting JSON.
12.4 Network Configuration Protocol (NETCONF)
See the dedicated org file on NETCONF
Network Configuration Protocol (NETCONF) is a network device configuration
management protocol that provides mechanisms to install, manipulate, and
delete configurations on network devices. It also provides a mechanism for
notification subscriptions and asynchronous message delivery.
Has four layers:
12.4.1 Content Layer
Contains the actual configuration and notification dataa.
12.4.2 Operations Layer
Defines a set of base protocol operations to retriev and edit the config
data. like <get>,<get-config>,<edit-config>, <lock>, <create-subscription>,
<kill-session>, and more.
12.4.3 Message Layer
provides a mechanism for encoding remote procedure clls. They ar encoded in
- RPC invocations, <rpc> message,
- RPC replies, <rpc-reply>
- RPC notifications <notification>
12.4.4 Secure transport layer
ensures a secure and reliable transport between client and server. (it uses
ssh, and hence TLS transport level security)
12.5 gRPC
ever increasing in popularity, it is open source, built with performance in
mind. Performance comes from using HTTP/2, so supports multiplexing requests.
gRPC uses a special format for data serialziation, called Protocol Buffers.
(which is a compressed binary format, before sending it)

13 REST Style APIs
REST is NOT a protocol. Respresentational State Transform, has endpoints
representing resources. When a REST API is called, the server tranfers a
representation of the state of the resource to the client.
- Was created with HTTP in mind.
Uses HTTP methodsas its set operations, so:GETPUTDELETE
- message serialization can be
JSON, plus others. simple- excellent
performance. - REST does not use a fixed response format
14 REST Overview
First, a common misconception is that :
REST means a server that exchanges JSON documents with a client over HTTP
This is not always true. The REST specification does NOT require HTTP or
JSON, in fact there is no mention of JSON or XML at all. See the REST
architectural constraints as follows.
Client-Serverarchitecture: theServermanages app data and state, while theclienthandles the user interactions. A clean separation of concerns so both can evolve independently, as long as their API (interface) is met.Statelessnesseach request stands on its own. Server keeps noclient state.Cacheabilitycan work, but need to indicate to all involved, and be careful you don't get stale data in responses. So, all responses must define themselves ascacheableornotUniform Interfaceclients only need the URI, they do not need to know the details of the server internals on how the responses were composed. So, the server messages must contain enough info to be self-descriptive, i.e the messages need to beHATEOAS,H.ypermediaA.sT.heE.ngineO.fA.pplicationS.tate
Layeredso that clients cannot tell whether it is connected to the end server or someintermediateload-balancer, proxy, or cache. A client may send a credit card payment that is actually processed by a financial provider, and not by the target web server. Client can't tell.Code on Demand, servers need to be able to send code to client sometimes. i.e. Javascript.- Data can be
streamed, so processing of large files can be done on the fly and not require large memory to store the whole thing. GOod for IOT and small IOT raspberry pies etc.
14.1 REST implementations
REST natively uses HTTP Methods.
| HTTP client | REST | |
|---|---|---|
| GET | getResource() | retrieves info |
| POST | createResource() | creates data |
| DELETE | deleteResource() | deletes data |
| PUT | update (replace) | replaces a field with data from body |
| PATCH | update | updates a field with request data |
| or creates the field if not exists |

But REST also gets benefits from standard HTTP cacheing, compreshion, encryption as well.
CRUD –> Create Read Update Delete
| Create | –> Post |
| Read | –> Get |
| Update (replace) | –> Put |
| Update | –> Patch |
| Delete | –> Delete |
Compare that with NETCONF actions:
| NETCONF | RESTCONF |
|---|---|
<get> |
GET |
<get-config> |
GET |
<edit-config> |
POST |
| PUT | |
| PATCH | |
| DELETE | |
<copy-config> |
? |
<delete- |
? |
config> |
|
<commit> |
? |
<lock> / |
? |
<unlock> |
|
<close- |
? |
session> |
|
<kill- |
|
session> |
? |
The ? because there RESTCONF does not have these functions???
14.2 Simple REST API in Python code example:
Bare bones:
import requests import json url = 'https://{{amp4e_client_id}}:{{amp4e_api_key}}@{{amp4e_host}}/v1/computers' response = requests.get(url=url, params=None) status_code = response.status_code content = json.loads(response.content) print(f' Status code: {status_code} ') print(f' Response content: {content} ')
Now with headers:
import requests url = 'https://{{amp4e_client_id}}:{{amp4e_api_key}}@{{amp4e_host}}/v1/computers' url = "https://85f5553ffa9425b99189: kWg1gxce-c14a-4shb-ss3a-a49hs2362yhdnapi.amp.cisco.com/v1/computers" payload={} headers = { 'Authorization': 'Basic ODVmNTUlas4mYTk0Mj23ggadfhr5uzdfgDQxZGUshdfhje34uyh34rtgfdbJdfgsfhhshhkerzQ1' } response = requests.request("GET", url, headers=headers, data=payload, timeout=400) print(response.text)
Notice there are more than one way to use requests. I should investigate if some are deprecated or they do different things.
15 Benefits of REST
Know this table.
| REST | SOAP | |
|---|---|---|
| Advantages | Better scalability, | Higher security and |
| performance and flexiblity | standardization | |
| Disadvtgs | Less secure and not suitable |
Increased complexity and |
for distributed environments |
poorer performance | |
| Message | Any | XML only |
| Format | ||
| Transfer | HTTP | Many; depends on the |
| Protocol | protocol | |
| Approach | Data-driven (data as a | Function-driven (data as |
| resource | a function call) |
16 POSTMAN
Is a REST client tool that let's you build requests and examine responses and save collections of requests in a collection. You can develop your app, or analyze how a web server works so that you can then build a script that automates a REST API to this web server.
See this very good document on Postman authorization, which is applicable to any REST API authentication: sending-request/authorization
16.1 Know the initial value vs current value
Initial values get shared when you share your collection, so DON'T put your keys here.
16.2 Know environments
The same collection can be played against a production or a test environ, so postman environements lets you set different variables when in one or another.
16.3 Code generation
Know how to get code.
16.4 Scopes in Postman
- global
- collection (initial) (broadest)
- environment (initial) (narrowest)
- ? I think there is also an override a specific request, i.e. adding a header manually. I think that that overrides my environment settings, and collection, adn global. >>>> I need to test this. <<<<<
17 API Constraints
Often the REST API response is too large to come back as a single response.
REST API benefits from the native HTTP functionality to break up large
requests into many smaller ones.
17.1 Pagination
Use URL parameters to set the page size limit, and page number as the offset.
Called offset pagination. Easy and safe. Mostly involves safely passing
those parameters to SQL as shown. Because all the data needed is contained
in the request, offset-pagination is stateless.

17.2 Native API pagination
Sometimes the API takes care of pagination by itself. You get links to
relevant pages in a response. These links contain the reference itself, and
links to the previous page, and the next page. If next page link is empty
or missing, you can assume the current page is the last page.
Native API pagination saves time, and makes code easier on the client, and increases efficiency, especially with large datasets.
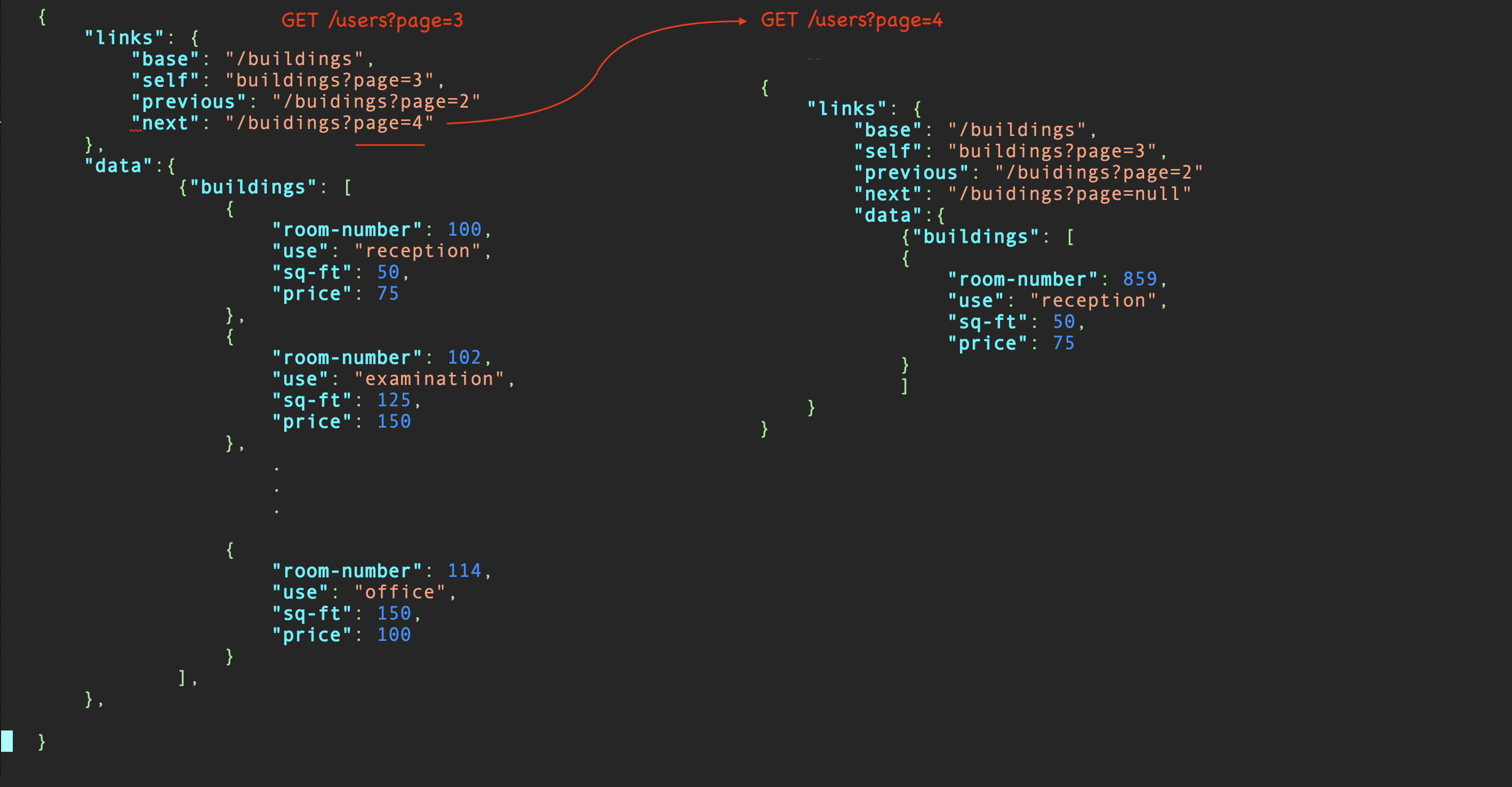
17.3 Cisco Web API standards pagination
RFC 5988 specifies how pagination is to work with this Cisco standard.
17.4 Filtering (and sorting) with URL parameters
This also utilizes the HTTP standards, this time using URL parameters.
For example:

17.5 Handling large server load
Even the best designed API can get bogged down in high load conditions. Fortunately there is rate limiting built into either the server side, or the client side.
17.6 client side limiting
Client-side rate limiting is usually implemented in the client application
and limits the client from performing a large number of tasks that are costly
for the API itself (with a timer, loading bar, or something similar). Here
you are limiting the rate of API requests sent to the web server.
17.7 server side limiting
- more effective
- can be
per user, say 1000 requests API calls per day, or if you pay a premium account 500 API calls per hour. - limiting requests/second would mitigate DOS attacks
- web servers can limit rates based on region too, i.e. Canada can limit requests/second from Russia or China.
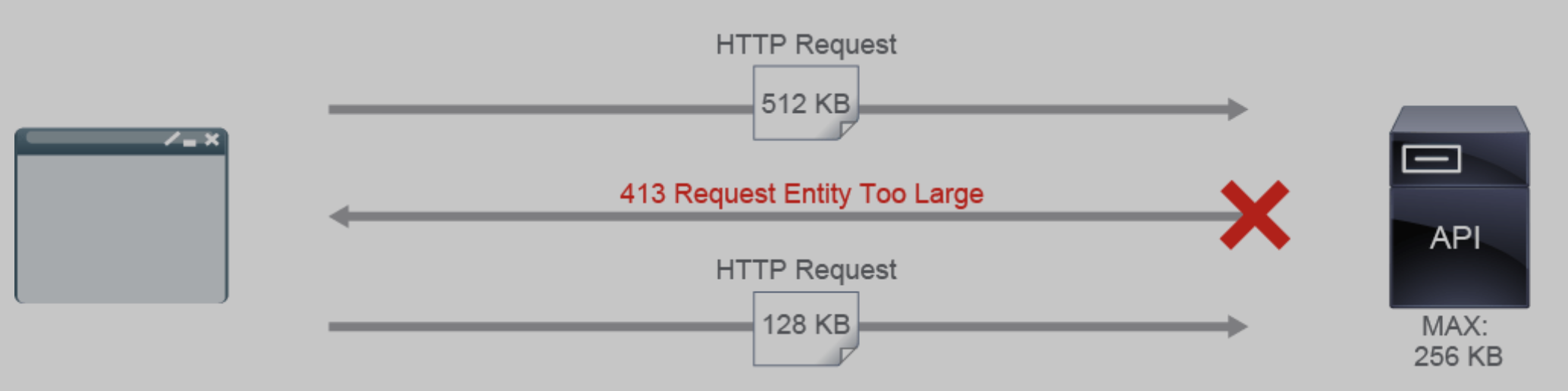
17.8 payload limiting
Is server-side limiting, that puts a limit on the size of the accepted
payload, in bytes. Think video upload to a cloud storage site.
By reducing the size of the body within a HTTP request sent by the client,
you reduce the chance of that request being corrupted while transporting,
increase the speed it can be processed, and limit damage someone malicious
could inflict by sending a 1GB size picture for example.
If payload is exceeded in size, the server will return 413 Request Entity
Too Large
API calls can be throttled using:
17.8.1 HTTP headers
Headers like X-RateLimit-Limit And X-RateLimit-Remaining are used to keep
track of the number of used and remaining API calls for a period of time.
17.8.2 Message queues:
Incoming API calls can be put into a queue, which makes sure the API
endpoint itself is not overloaded.
17.8.3 Software libraries and algorithms:
Many libraries and algorithms have been created for the purpose of rate
limiting, such as leaky bucket, fixed window, and Sliding Log.
17.8.4 Reverse proxies and load balancers:
Load balances and reverse proxies (like NGINX) feature rate limiting as a
built-in feature.
17.9 429 Too Many Requests HTTP response code.
The response code 429 often includes a Retry-After header that tells the client how long
to wait before trying again.
It makes sense to expect a certain amount of problems when using remote APIs.
Therefore, your code should handle those errors, and even, where available,
check on the health of the service, before sending a big request. Therefore,
writing good code means checking for status of APIs and waiting to retry
rather than just crashing with a Traceback. For example a client might use
this to check API health:
Example of a simple API Health Check
def checkStatus(url): try: # Check API Status status = requests.get(url + "/api/status") if status.status_code != 200: raise Exception("Unexpected status code: " + status.status_code) except Exception as e: print(f" API endpoint encountered an error: {e} ")
More detailed client might implement something that retries reading users 10
times with 30 second intervals in-between. Each time, the client checks for
HTTP code 200 OK because that means the request did not time out.
Also, you requested "users" but the response might contain different data, so
it is best practice to trust but verify, i.e. make sure you are getting what
you expected to get.
import requests def getUsers(url): max_retries = 10 timeout = 30 for retry_count in range(max_retries): try: api_users = requests.get(url + "/api/users") except Exception as e: print("Error encountered while reading users.. Retrying") if api_users.status_code == 200: return api_users else: time.sleep(timeout) raise Exception("Retry limit reached!")
You can use these time-out schemes:
linearfor example (5, 10, 15, 20)exponentialfor example (1, 2, 4, 8, 16, 32)
Timeouts produce 408 Request Timeout (unless server is acting as a proxy in which case it would be 504 Gateway Timeout ) Unless the server is a simplistic one, in which case youtmight only see 404 Not Found
18 Authentication
Authenticationproves who you are.Authorizationcontrols what you can do.API keysidentify the calling project - the application or site - making the call to an APIAuthentication tokensidentify a user - the person - that is using the app or site.
19 REST API Authentication
Most REST APIs use HTTP headers to store various authentiation credentials.
To make a REST API request often need to authenticate. Reading the REST API documentation will indicate what if any authentication is needed. Some common authentication methods include
- sending a
usernameandpasswordthat then gets anexpirable token. This is a combination of Basic HTTP authentication and Custom token authentication - Others use an
OAuth2protocol and integrate with an identity provider that clients authenticate against. For example, Webex teams APIs implement BOTHOAuth2andself-issued tokensfor Bot accounts and for developer testing purposes. API key(need the key first) For Cisco Meraki, once you enable API access using your logged in user in dashboard.meraki.com,clients can generateanAPI keyfor programmatic use, andcopy that to their script.
But Typically you will use Basic Authentication with RESTCONF, passing
username and passwords from the client to the server via an "Authentication"
header.
There are three general apporaches that REST APIs use for authentication, and 1) Basic authentication, 2) API key authentication 3) Custom Token authentication .
19.1 1) Basic HTTP authentication (for users)
uses the native/built-in http authentication
- Con: every API request must have
authentication details(same for API key). (compare withcustom tokenwhereno authenticationdetails are sent. Instead, a token is sent)
19.2 2) API key authentication (for programs/apps)
uses pre-generated API keys that client adds to a header (usually X-API-Key)
- Con: every API request must have
authentication details(same for basic auth). (compare withcustom tokenwhereno authenticationdetails are sent. Instead, a token is sent) - client manually adds the pre-generated key to the request
servergenerates the key in an earlierbasic authenticated web session- the key is
Base64 encoded, so it can be transported via HTTP - key can use HTTP
headers, eitherAuthentication:orAuthorization: - key can use
URL parameter - key can use
cookies, (i.e. as a header)The server receives the request, parses it, decodes the key, compares to a table containing valid keys, then either allows or sends
401 Unauthorizederror in the response.
In python, using the requests built-in module it would look like:
headers = {'X-Api-Key': 'gahwo135n2nf'} payload = {'user': {'name': name, 'age': age}} response = requests.post(url | '/users', headers=headers, data=payload)
Invalid keys lead to 401 Unauthorized response error codes.
If key is good, but you are not authorized to do the job, you will gets
403 Forbidden.
- Weak, as the same key is sent in every single request, can be compromised
- Custom tokens solves this problem, but they are for users, not apps/scripts
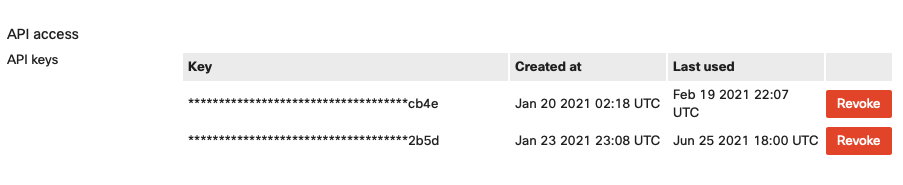
Under Meraki's dashboard, under account profile, I can generate a new meraki key, or revoke a compromised meraki key:
Using these keys as a URL parameter
GET /users? api_key=28fnhu781gab44
Using these keys as an HTTP cookies
GET /users Cookie: api_key=28fnhu781gab44
19.3 3) Custom Token authentication (for users)
A dynamcially generated token is used. Also known as access token.
Here's the process:
- a client tries to access the web server
- client is
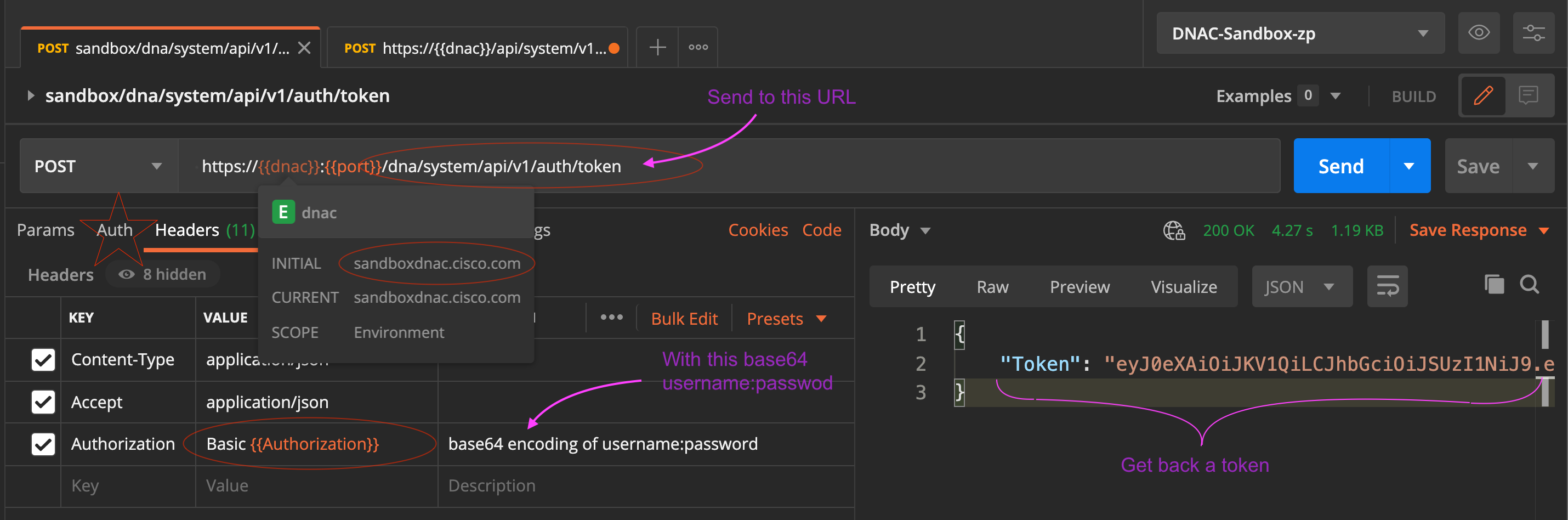
not authenticated, so client is redirected to anauthenticationserver. where client providesusername:password(i.e. basic auth). This is done with a POST request for example to:htps://sandboxdnac2.cisco.com/dna/system/api/v1/auth/tokenusername:password in base64 encoding(lets say that is stored in {{myusepass64}} in the headers of the request.Authorization: {{myusepass_64}}would be the header used by Postman.
Authentication servervalidates the credentials given, andgeneratesa custom, time-limited, signedauthentication tokenand returns it in theresponse- client requests now contain this proper, valid token in
headers, orURLparametersor cookies?, and that is passed to the API - The API services
validatesthe token and servers up the response.
In theory this is what is happening:
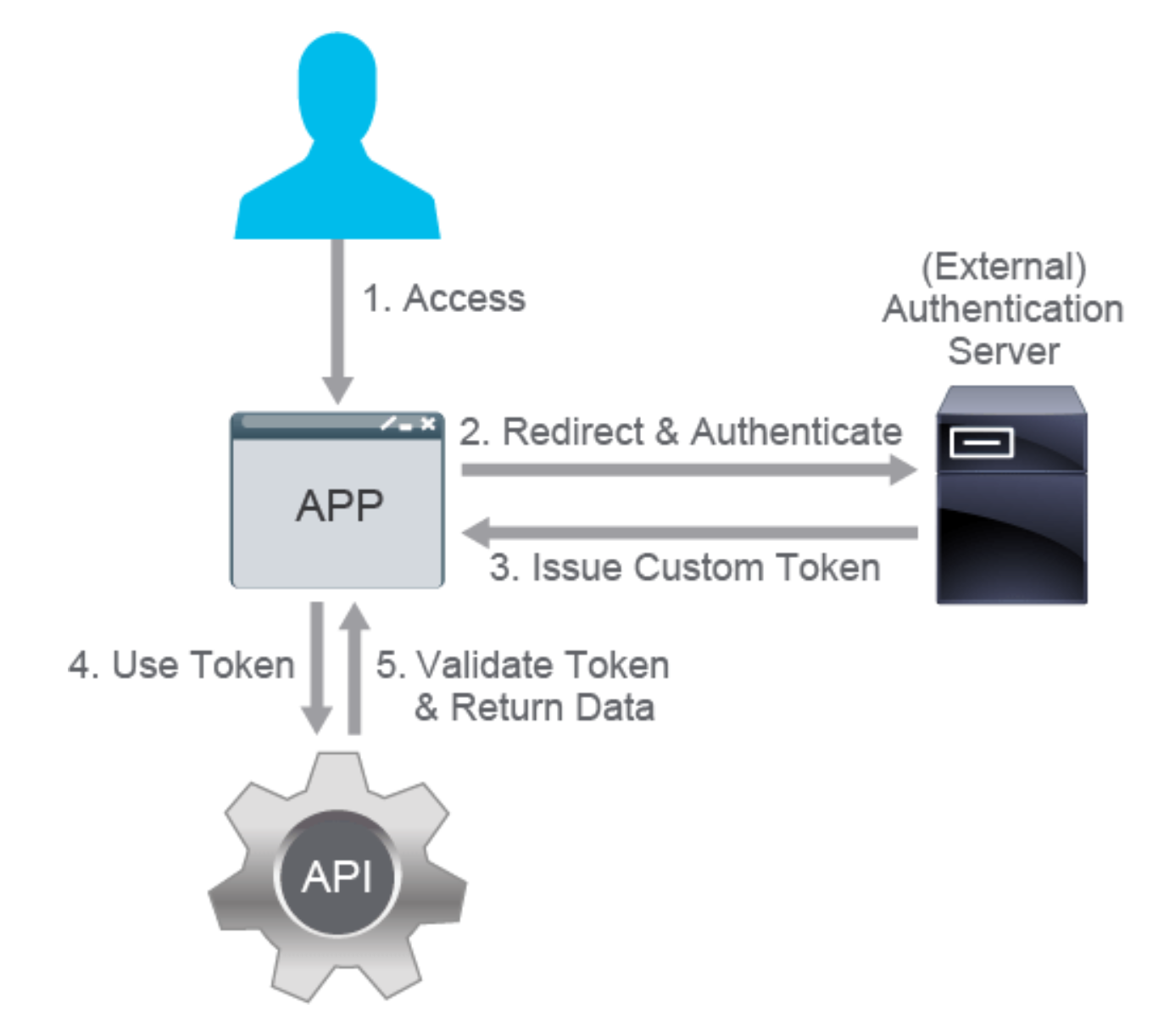
The authentication server is often an external service (for example, OpenID)
that is used in combination with an authorization mechanism (for example,
OAuth 2.0). The tokens themselves often contain some authorization data as
well. Authentication servers are commonly used to issue tokens that can be
used with many different services from different vendors (for example, using
Google authentication to log in to an unrelated site that has implemented
Google sign-in).
The term that is commonly used for this type of authentication (and
authorization) is single sign-on (SSO). SSO is gaining in popularity, because
it is very useful for services that require third-party authorization (for
example, sharing an article from a news site on a social media account) or for
businesses that offer several different services but want users to use the
same identity for all of them (for example, Google Apps, your company
enterprise environment, and so on).
The pros of custom token authentication include: Pros:
19.3.1 Faster response times:
Only the token (and maybe its session) has to be validated instead of the
credentials. Sessions are often kept in very fast in-memory databases (for
example, Redis), while credentials are kept in nonvolatile memory relational
databases.
19.3.2 Simplicity of cross-service use:
This reduces the number of the authentication systems needed in an organization and unifies authentication and authorization policies across the services.
19.3.3 Increased security:
The credentials are not passed with every request, but rather only once in
the beginning and periodically after that when the token expires. This way,
it reduces the chance of success and viable time frame for any
man-in-the-middle or cross-site attacks.
Cons: While offering a step forward in most areas of authentication, custom token authentication is:
19.3.4 a bit more complex than the other types.
19.3.5 less control
There is also less granular control over individual tokens, because in case the private key of the authentication server gets compromised, all the tokens must be invalidated.
19.4 3) Custom Tokens continued, Oauth 2.0
A modern standard for authorizing network connections between disparate services.
- allows an app to post to your twitter feed.
- allows a login to github using Google account
- allows IOT device, like a temperature sensor and its cloud based back end, post daily temperature readings in a google sheets, or google docs
- allows an API or CLI on your laptop access remote public cloud service without storing your username/password in that API, or CLI.
- Allows SSO, a single corporate user login access to a bunch of websites, services, and applications.
As you can see OAuth2.0 is really just an implementation of Customer Token
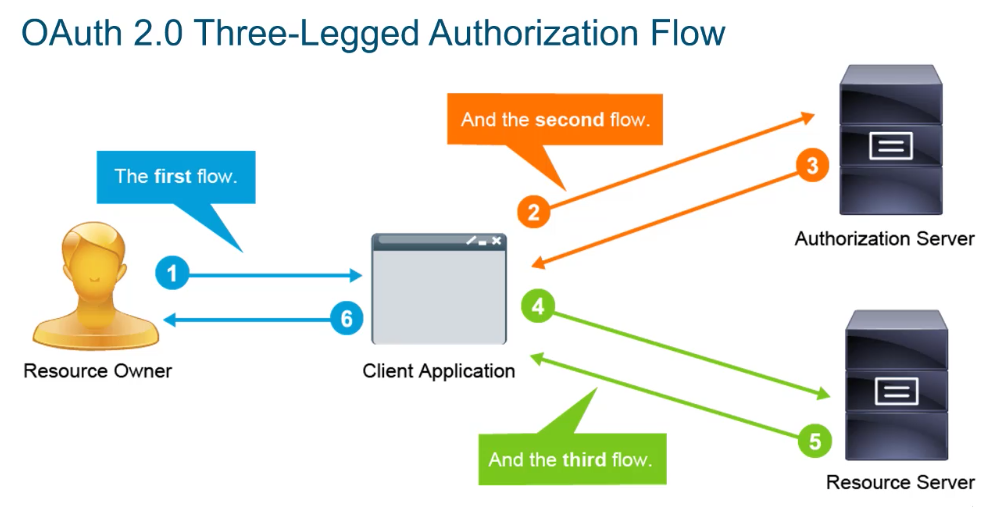
19.4.1 OAuth2.0
Benefits:
- protect client secrets
- simple clients and resource servers (no need to store sensitive info)
- easy to renew and revoke access to resource servers
- exposing an expiring (short lived) tokens is not as problematic as exposing username and password
- tokens are anonymouse, so they do not leak sensitive info, i.e. which user, which server, which app?
- authentiation can be done on a per-message basis instead of per session, which can be highjacked.
19.4.2 Cisco and OAUTH
- uses resource owner name and password as the authorization grant mechanism i.e. "Basic Auth" for authorization grant mechanism.
Because the client and the resource owner are the same entity, the workflow can be simplified to this:
- first request: include username and password to request a token for
subsequent requests.
- headers have username and password
- that is formed by concatenating the string "Basic" with base64 encoding of the username:password,
- OAuth uses the received token in the X-Auth-Token field in headers that
are sent to authenticate the action. Usually in json format:
{ "Token": " all subsequent requestsuse this e X-Auth-Token header
19.5 Comparing these 3
- API keys need to be store, and they are static, so they are not as secure.
- Basic auth encodes username:password in Base64, but that is not encryption just an encoding, that is easy to decode, so less secure.
- hashed credentials are more secure, because credentials are never sent in the clear.
- Basic http auth parameters
19.6 Authentication when a proxy is used
To handle HTTP authentication through a proxy, one can use special proxy headers.
20 HTTP built-in authentication
HTTP authentication uses several different authentication schemes:
- Anonymous (no authentication)
- Basic (Base64-encoded credentials as username:password)
HTTP has its own authentication process that your API can use. The process goes like this:
- a client makes a request to an HTTP server. If the request is
unauthenticated (and hence unauthorized), the server's response is a
401unauthorizedwith a WWW-Authenticate HTTP header in the response. - The client examines the returned header, and picks which authentication method should be used to gain access to the resource. The header could have several methods offered.
- the client sends another request, this time including the Authorization
header, that contains the a)
authentication typeand b)credentialsThe realm is what resources the client is asking for, and normally should have access to on the server - The server responds with a
200 OKor a403 Forbidden!depending on the results of the credential check.
A UML sequence diagram of the HTTP messages exchanged bewteen the client and server:

20.1 HTTP authentication schemes:
There are several:
- Anonymous (no auth)
- Basic (Base64-encoded credentials as username:password)
- Bearer (HTTP implementation of custom token authentication)
- Digest (MD5-hashed credentials)
- Mutual (2-way auhentication)
- Others (uncommon) such as HMAC, HOBA, AWS, OAuth, Negotiate…
These ALL should be used with TLS, i.e. https as a minimum.
Example:
import requests import base64 def authenticate(url, username, password): auth_type = 'Basic' creds = '{}:{}'.format(username, password) creds_b64 = base64.b64encode(creds) headers = {'Authorization': '{}{ {}'.format(auth_type,creds_b64)} try: response = requests.get(url, headers=headers) if response.status_code != 200: raise Exception('Authentication error: {}'.format(response)) except Exception as e: print('Authentication unsuccessful! Error returned was: {}'.format(response)) print('Authentication successful!')
20.2 Create a new user using API key authentication using Python
This example, taken from Cisco Devnet shows how one can create a new user, using API key authentication.
def createUser(url, name, age): headers = {'X-API-Key': '28fnhu781gab44'} payload = {'user': {'name': name, 'age': age}} try: response = requests.post(url + '/users', headers=headers, data=payload) if response.status_code == 401: raise Exception('API key invalid') elif response.status_code == 403: raise Exception('API key not authorized!') elif response.status_code != 200: raise Exception('API error: {}'.format(response)) except Exception as e: print(f'User creation failed! Error:{e}') print('User creation failed! Error:{}'.format(e)) print(f' User {name} created successfully!')
20.3 Where to find the REST API documentation
Usually REST API documentaiton is written to open standards, such as OpenAPI(Swagger) or RAML. Cisco DevNet site publishes them under these menus. Start at developer.cisco.com
20.4 Webex Authentication
Right out of help(api) where api = WebexTeamsAPI() in python.
#+BEGINEXAMPLE An access token must be used when interacting with the Webex Teams API.
| This package supports three methods for you to provide that access |
| token: |
| 1. You may manually specify the access token via the `accesstoken` |
| argument, when creating a new WebexTeamsAPI object. |
| 2. If an accesstoken argument is not supplied, the package checks |
| for a WEBEXTEAMSACCESSTOKEN environment variable. |
| 3. Provide the parameters (clientid, clientsecret, oauthcode and |
| oauthredirecturi) from your oauth flow. |
| #+ENDEXAMPLE |
21 HTTPS
Secure version of http, using TLS, transport layer security. It uses digital certificates. TLS replaces the older SSL. Port 443 is the default port.
- the TLS session needs to be established first
- Still, HTTPS is considereda a
statelessprotocol. - uses public key cryptography. Uses key pairs, and public and private keys.
- public keys are known as "certificates".
- public-private key cryptography a.k.a. asymetric cryptography.
21.1 Digital certificates
- provide identity, called
"public certificates" - signed by a trusted third party, called "
certificate authorities". public keysare thenretrieved from this third party, to make it harder for both pairs of keys between two parties being intercepted, and replaced, in a "man in the middle" attack.
21.2 Global, trusted CAs
Only a few global certificate authorities exist. They are GoDaddy.com,
IdenTrust, Comodo, Let's Encrypt.
- use a trust chain, of signed certificates that are themselves signed by other trusted certificates.
- Info in a certificate is defined in the X.509 standard.
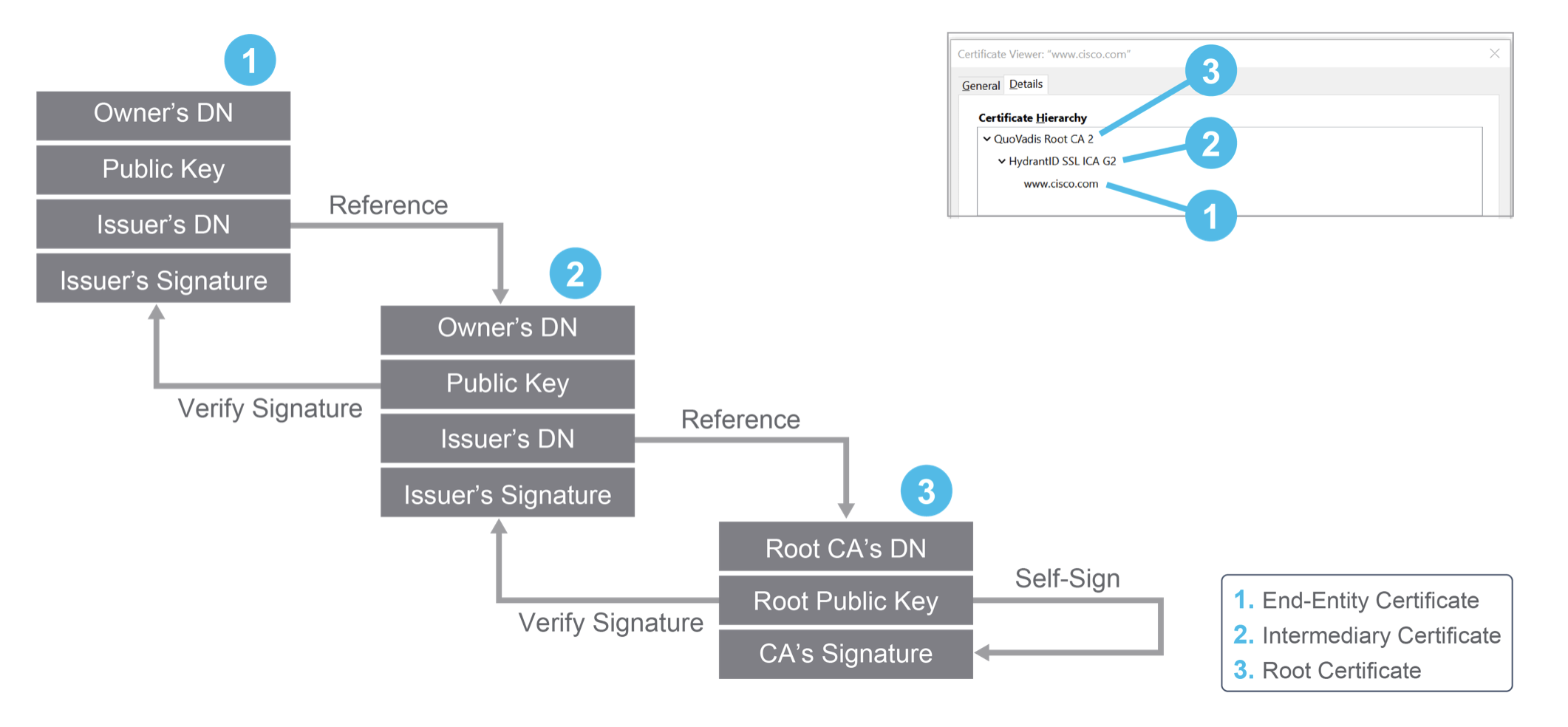
21.2.1 X.509 standard
Certificates that are X.509 standard, contain these fields
- public key owner
- DN of owner (Distinguised Name)
- DN of CA
- valid from and expiry dates
- unique serial number of certificate
- protocol information
Some digital certificates are:
- single domain - applies to only one hostname.
- wildcard - applies to an entire domain and its subdomains
- multidomain - applies to zintis.net and perkons.com
21.3 TLS handshake
Initiated by the client.

This depicts using RSA encryption algorithm. Other algorithms may or may not exchange secrets the same way, i.e. keyless SSL, Diffe-Hellman
Risks are at the TLS handshake phase, and HTTPS itself, though low, or a compromised CA. All the attacks attempt to be a MIM, man in the middle.
Risks are:
- HTTPS spoofing
fake certificatesare sent to theclient, thus making theclient trust your connecionas a real one - SSL hijacking
fake authentiation keysare copied to the client and server, thus getting full access (unencrypted in the middle) to the connection. - SSL stripping converts the
httpsconnection to ahttpconnection byinterrupting the TLS handshakeand exploitingHTTP redirects - Downgrade attacks abuses systems that try to support
backward compatibilityby insisting the connection use anolder, less secureorless protectedversion of s/win order toexploit known vulnerabilitiesin the old s/w. - Software bugs for unpatched systems, known bugs are disastrous, for example, heartbleed was such an exploit.
- Phishing attacks trick the user to accept a fraudulent certificate. 'nuff said.
21.4 Handling Secrets in APIs
Keep your certs, your API keys, your tokens secure!! They are the weakest
link in your security chain. The solution is proper Credential Management.
Principles to live by:
Avoid hard-coding credentialsin scripts/programs- lead to loss of portability
- loss of flexibility
- poor management. think about upgrading credentials in all your various scripts and files. this would take lots of time and be error prone
- is insecure if for instance you store your code in a revision mgt system such as git. There for the taking/stealing!!
- Use
softcodingof your credentials. That means retrieving your credentialsfrom an external sourcefor instance:- environmental variables
meraki_user = os.environ["MERAKI_USER"] - external env modules
- configuration files # you could
import configparser - use cookies
cookies = {'cookies': f'api_key={}'}
- environmental variables
- mind your
loggingFirst of all, take care when you write messages to a log file, that those messages never contain credentils. Secondly, a good idea to periodically search your logs for credentials, and fix them before someone else finds them and hacks you.- Use a true-fals switch for logging sensitive info. i.e. log lots in
dev, but very little inprodenvironments. - Regularly "mask" credentials in logs, if they ever do appear. Similar
to the concept of
egress filteringon firewalls that strip credit card info, or credentials on traffic exiting a firewall. - implement credential partitioning for users, with different credentials needed for different tasks.
- Use a true-fals switch for logging sensitive info. i.e. log lots in
- Mind your
http headersif you send credenti~als as headers, make sure it is https and not http. Encrypt data at restIn transit it should be encrypted by TLS, but at rest use symetric key encryption to encrypt/decrypt credentials when you need them. Will needeffective key managementto keep track of the different keys for the different functions of your project. Encrypting data at rest can be:- full disk encryption
- file system encryption
- database encryption
22 XSS has to be monitored.
Hackers can run their own code inside your web server if you don't protect yourself.
23 php
A web page that contains the tags <?php …. ?> tells the server to
interpret the code within these tags and execute it. The code is called
a php script and the execution is done on the server, so this is also called
server-side scripting. If you want to run code on the client, the web page
can contain java script code. This is called client-side scripting.