Software Design and Design Patters
1 Organizing code into methods / functions, classes, modules
These are techniques/tools to let you follow Modular Design Principles
Writing good modular programs means following some common, well tested
principles.
Acyclic dependenciesprincipleStable dependenciesprincipleSingle responsiblilityprinciple
1.0.1 Acyclic dependencies principle
Avoid loops in dependecies. i.e. a calls b calls c calls a if c is a method in module two, then c should not be calling method a that is in module one.
'

1.0.2 Stable dependencies principle
Packages should depend in the direction of stability. This means that every
package should depend only on packages that are more stable than the package
itself is.
1.0.3 Single Responsibility principle
Every module, class or function in a computer program should have responsibility over a single part of that program's functionality, and it should encapsulate that part. All of that module, class or function's services should be narrowly aligned with that responsibility.
1.1 Methods/Functions
Help with the DRY principle, "don't repeat yourself". Code is written once,
then reused many times. Also, each method/function should implement only a
part of the functionality provided by the software. This is called the
- single responsibility principle.
- single responsibility principle.
Two benefits of separating s/w code into modules are:
- Code can be
separated from the restof the application - Module code can be
reusedbymultiple applications
Code that does a single thing, but that can be called from many places.
Lets you divide your code into small reuasable chunks. Always write a
function when you start repeating the same code in more than one place.
You should follow DRY principle "Don't Repeat Yourself"
1.1.1 keywords passed to a function are called arguments.
Used if a function needs some input on which to operate. Arguments are optional, depending on what your function does.
1.1.2 return
Some functions just do a task, end, & that's it. Others return a result
to the calling code. That is done with the return statement.
1.1.3 variable scopes
Some variables are used just within the function and then are not needed
anymore once a return is executed. These are called local variables and
have a local scope. These variables are NOT available outside the function.
Other varibles are defined in the main program and are available to all
parts of the program and functions defined in the program. When at all
possible keep variables local, so that inadvertent bugs do not creep in
where a global variable is being modified in two (or more) places, and
messing up your code.
1.1.4 naming functions
Names should be short, but describe what the function does. (and that should be a single thing, so easy to desribe in one sentence.)
1.2 Classes
Creating a class means creating a new TYPE of object, not an instance
of a type of object. x = 3 simply creates a new instance of an integer
class object, and assigning it to "x". But creating a class is creating
a new TYPE.
The new TYPE of object allows new instances of that type to be made. Each class instance can have attributes attached to it for maintaining its state. Class instances can also have methods (defined by its class) for modifying its state.
Benefits of classes (object oriented programming)
modularityfor easier troubleshootingReuseof code through inheritanceFlexibilitythrough polymorphismEffective problem solving(breaking down problme into smaller easier ones)
Antoher source has these 3 benefits to classes (oop)
MAINTAINABILITYObject-oriented programming methods make code more maintainable. Identifying the source of errors is easier because objects are self-contained.REUSABILITYBecause objects contain both data and methods that act on data, objects can be thought of as self-contained black boxes. This feature makes it easy to reuse code in new systems.Messages provide a predefined interface to an object's data and functionality. With this interface, an object can be used in any context.SCALABILITYObject-oriented programs are also scalable. As an object's interface provides a road map for reusing the object in new software, and provides all the information needed to replace the object without affecting other code. This way aging code can be replaced with faster algorithms and newer technology.
1.2.1 Why classes are more than just dictionaries.
Classes can have:
methods(any function inside a class is called a "method")initializationhelp text
- Init method (a.k.a. "constructor")
def _init__( self,
The init method is called every time you create a new instance of this class. Said in other words, the init method is always called the first time you create an object of this class.
The first argument is always called "self". It is a reference to the new object being created.
The additional arguments are optional. If they are added, then you must store these values in fields, using the self. syntax as below:
def __init__(self, argument2, argument3) self.field2 = argument2 self.field3 = argument3 import datetime class User: ''' this docstring will be displayed if one issues help(User). The class has two methods, init and age. ''' def __init__(self, full_name, birthday): self.name = full_name self.birthday = birthday # can store the value in birthday in a field called birthday. # so be careful when coding. The second 'birthday' in that line is # the value provided when you create a new instance of the object # the first 'birthday' is the name of the field where we will store # this provided value. # Expanding the init method, we can extract first and last names name_pieces = full_name.split(" ") # this will store strings split on spaces into an array. self.first_name = name_pieces[0] self.last_name = name_pieces[-1] # just look at the last string # self.last_name = name_pieces[1] # would give you the second string # which might be an initial, and not the last name # Note that we can create variables in the method, but they exist # only inside the method and are killed when the method exits. # i.e. first_name = name_pieces[0] would NOT assign anythying to the # object def age(self): ''' Return the age of the user in years. ''' yyyy = init(self.birthday[0:4]) mm = init(self.birthday[4:6]) dd = init(self.birthday[6:8]) dob = datetime.date(yyyy, mm, dd) age_in_days = (today - dob).days age_in_years = age_in_days / 365 return int(age_in_years) # Now we can create an object, let's call it 'user': user = User("Michael Palin", 19430505) print(user.age()) # will print 80 if you run this in Nov, 2019 help(User) to see all sorts of additional info to the docstrings you added.
From devnet:
"Class is a construct used in an
object-oriented programming (OOP)language. OOP is a method of programming that introduces objects. Objects are basicallyrecords or instances of codethat allow you tocarry data with themandexecute defined actions on them. It represents a blueprint of what an object looks like, and how it behaves is defined within a class.Class is a formal description of an object that you want to create. It will contain
parameters for holding dataandmethods that will enable interactionwith theobjectand execution of defined actions. Classes can also inherit data from other classes.Class hierarchies are made to simplify the code by eliminating duplication.Every language has its own way of implementing classes and OOP. Python is special in this manner because it was created according to the principle
"first-class everything."Essentially, thisprinciplemeans that everything is a class in Python.See Object Oriented Programming OOP section in python.classes.org file.
2 Object Oriented Programming OOP
Object Oriented Programming has formally defined properties:
- encapsulation
- data abstraction
- polymorphism
- inheritance
2.1 encapsulation (think private variables)
Encapsulation in OOP conceals the internal state and the implementation of an
object from other objects. It can be used for restricting what can be
accessed on an object.
You can define that part of data that can be accessed only through designated
methods and not directly; this is known as data hiding.
In Python, encapsulation with hiding data from others is not so explicitly
defined and can be interpreted rather as a convention. It does not have an
option to strictly define data being private or protected. However, in
Python, you would use the notation of prefixing the name with an underscore
(or double underscore) to mark something as nonpublic data. When using the
double underscore, name mangling occurs; i.e in a runtime that variable name
is concatenated with the class name.
If you have a __auditLog() method in a device class, the name of the method
becomes _Device__auditLog(). This is helpful to prevent accidents, where
subclasses override methods, and break the internal method calls on a parent
class. Still, nothing prevents you from accessing the variable or method,
even though, by convention, it is considered private.
class Device: def __auditLog(self): # log user actions pass def action(self): # perform desired action and log (self.__auditLog() # private methods can typically called only # within the same class
2.2 data abstraction
modules, classes or finctions directly.
The ambition of an abstraction is to hide the logic implementation behind an
interface. Abstractions offer a higher level of semantic contract between
clients and the class implementations. When defining an abstraction, your
objective is to expose a way of accessing the data of the object without
knowing the details of the implementation.
Abstract classes are usually not instantiated; they require subclasses that provide the behavior of the abstract methods. A subclass cannot be instantiated until it provides some implementation of the methods that are defined in the abstract class from which it is derived. It can also be said that the methods need to be overridden.
2.3 polymorphism
Allowing routines to use variables of different types at different times.
Goes hand in hand with class hierarchy. When a parent class defines a method
that needs to be implemented by the child class, the method is considered
polymorphic, because the implementation would have its own way of presenting
a solution than what the higher-level class proposed.
Polymorphism is present in any setup of an object that can have multiple
forms. when a variable or method accepts more than one type of variable, it
is polymorphic.
2.4 inheritance
Already discussed in python classes.
2.5 Classes are more than just dictionaries.
Classes can have:
datamethods(any function inside a class is a "method", or "class method")initializationhelptext
Python Classes provide all the standard features of object oriented programming.
Python uses classes because classes allow us to logically group our data
and functions in a way that is easy to reuse, and easy to build upon if
needed. Think of it as simply bundling 1) data and 2) functionality on that
data. Thus accomplishing the "data abstraction" property of OOP
Can also think of classes as "a template for creataing objects with related 1) data, and 2) functions that do interesting things with that data" - Socratica
New classes can be defined based on existing classes. When they do they
inherit the properties, data, and functionality of the existing class.'
In python you do NOT have to predeclare instances of objects. They get declared/created the first time you use a class to create a class instance.
Outside of the class, you refer to methods inside the class as class.method i.e. use the "dot" notation.
variables declared inside a class are not private. But by convention only people use _varname for variables intended to be private (i.e. used only within the class or function.
See docs.python.org for detail on classes and methods.
2.6 Modules
Independent, python code, able to be imported into other code, and thus reused many times.
Grouping more complicated code, that can have several functions (methods)
inside can be done by saving the code into a separate python script, and
then importing that script into your own program. These seperate python
scripts are called modules
You can write your own modules
You can import modules from the standard library
You can import modules from other repositories from various sources.
Modules are python programs, hence end in .py. However because there is
no other type of import that one can do in python, you do not have to
include the .py at the end. It is implied.
When a module is imported, it gets executed right away. If you need to
re-execute a module in its entirety, you use the reload call, but that is
rare.
Functions within these modules are called methods. They can be called by
your main program using the "dot" notation module.method.
You can run a module directly, in which case it takes the name "main" or you can import it into another program, in which case its name is the same as the module's name itself. hence the: ~if _ name _ = _ main_ block.
#########################################################################
3 Unified Modelling Language, UML
This is taken from the Devasc study group materials: (without permission, so private use only.)
The Unified Modeling Language (UML) was created because programming languages, or even pseudocodes, are usually not at a high level of abstraction. UML helps developers to create a graphical notation of the programs that are being built. They are especially useful for describing, or rather sketching, code written in object-oriented style.
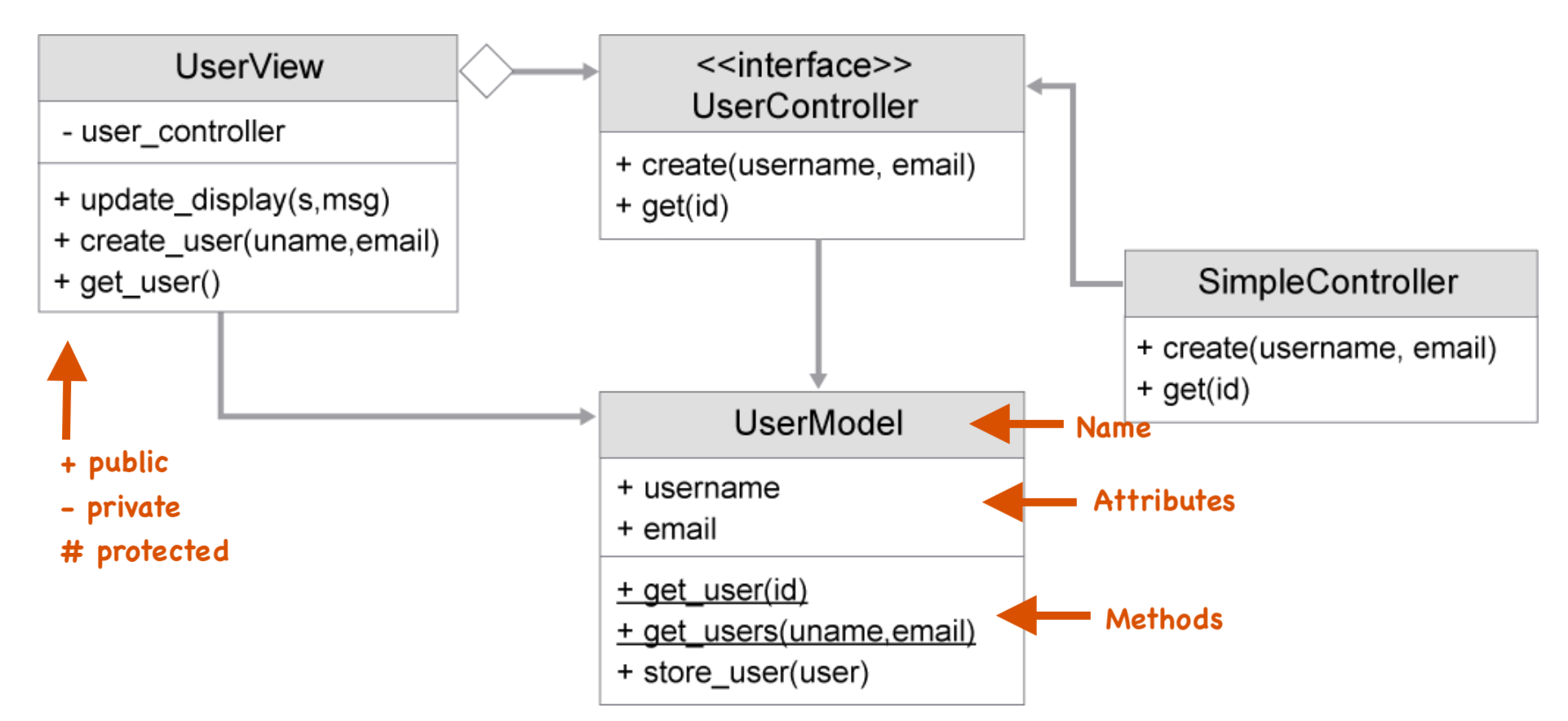
The UML can sketch your program before you start writing code for it. It can define many details of a class and the connection between other classes. In this example, the Router object would inherit all the fields and methods from the Device object. Class inheritance is shown with a solid line and an arrow at the end.
You can use UML as part of the documentation for a program, or use it for reverse-engineering an existing application, to get a better picture of how the system works.
####################################################
4 Common Software Architecture patterns
- Layered or multi-tiered architectural pattern
Model-View-Controllerarchitectural pattern- Microservices architectural pattern
Event drivenarchitectural pattern- Space-based architectural pattern
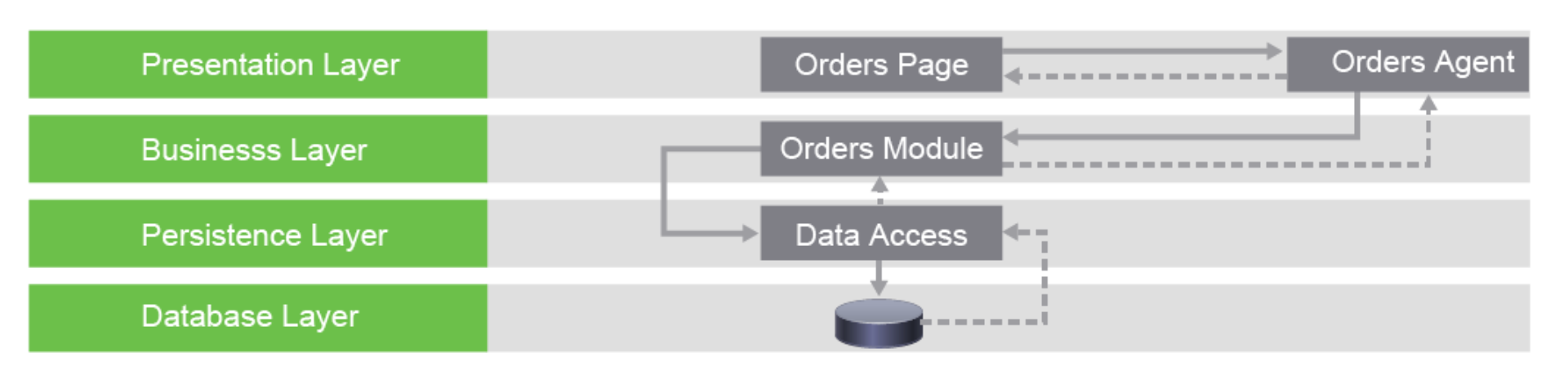
4.1 Layered / Multi-tiered architectural pattern
Most common of all. Each layer performs a specific role in the application.
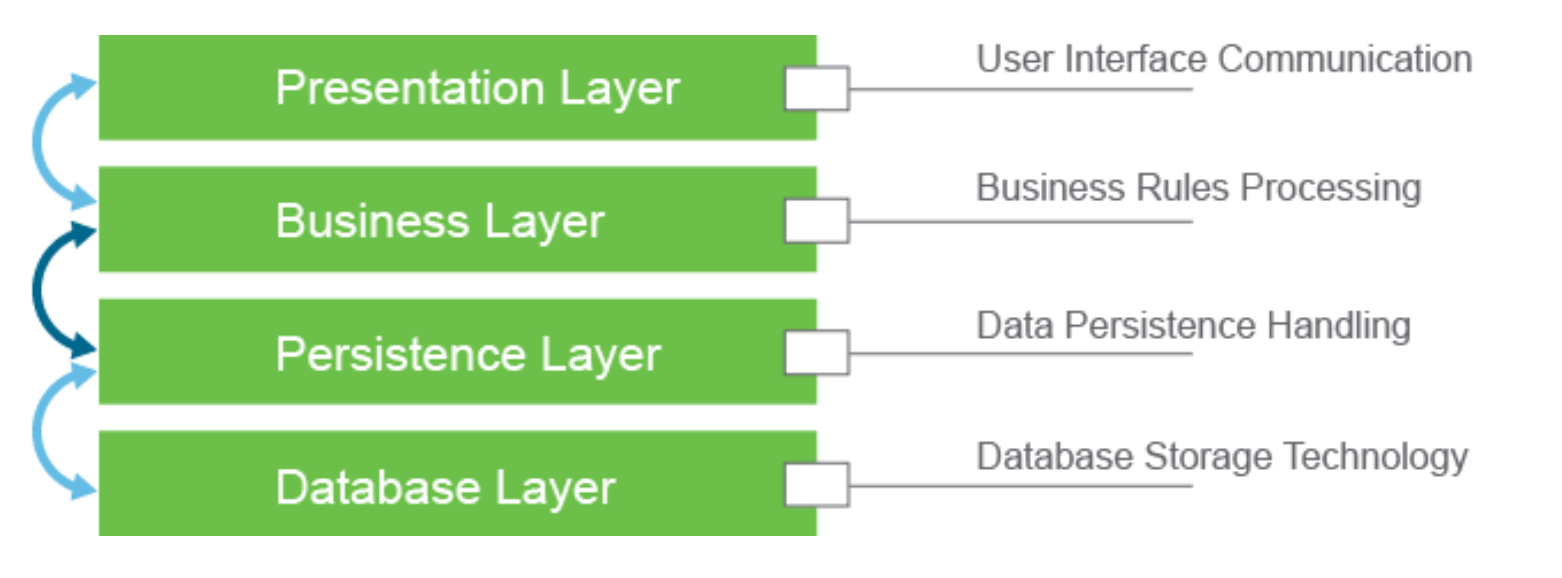
Since Business Layer and Pesistence layer are often combined, also known as
3-layer arch. pattern
- Presentation layer handles logic for
user interfacing, takes user input, and returns output. - Business layer performs specific
business rules, based oneventsoruserrequests - Persistence layer handles requests for data through
sql queriesto the database layer database layer
Each layer keeps to its own layer, so easier to develop and maintain apps.
Layer "skipping" is NOT allowed, so the presnetation layer should NEVER
directly access the database layer, etc.
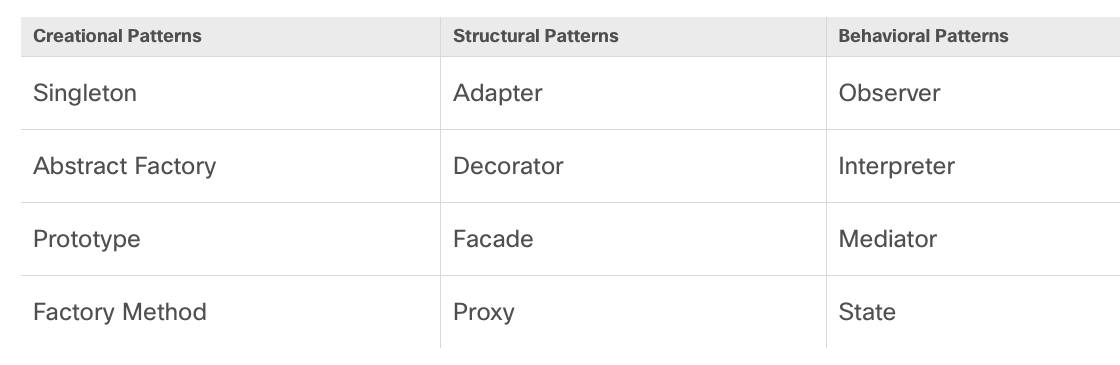
4.2 MVC
First off the Gang of Four published a book on s/w design patterns that
revolutionized s/w development. They classified three main categories of
design patterns:
- Creational - the patterns concerned with the
classorobjectcreationmechanisms. They are used to guide, simplify, and abstractsoftware object creationat scale. - Structural - deals with the
classorobjectcompositions formaintainingflexibilityin larger projects; Patterns describing reliable ways of using objects and classesfor different kinds ofsoftware projects. - Behavioral - describes
ways of interactionbetween classes or objects. Patterns detailinghow objects can communicateandworktogetherto meet familiar challenges
4.2.1 MVC
Model–view–controller is a software design pattern commonly used for
developing user interfaces that divides the related program logic into three
interconnected elements. This is done to separate internal representations of
information from the ways information is presented to and accepted from the
user.
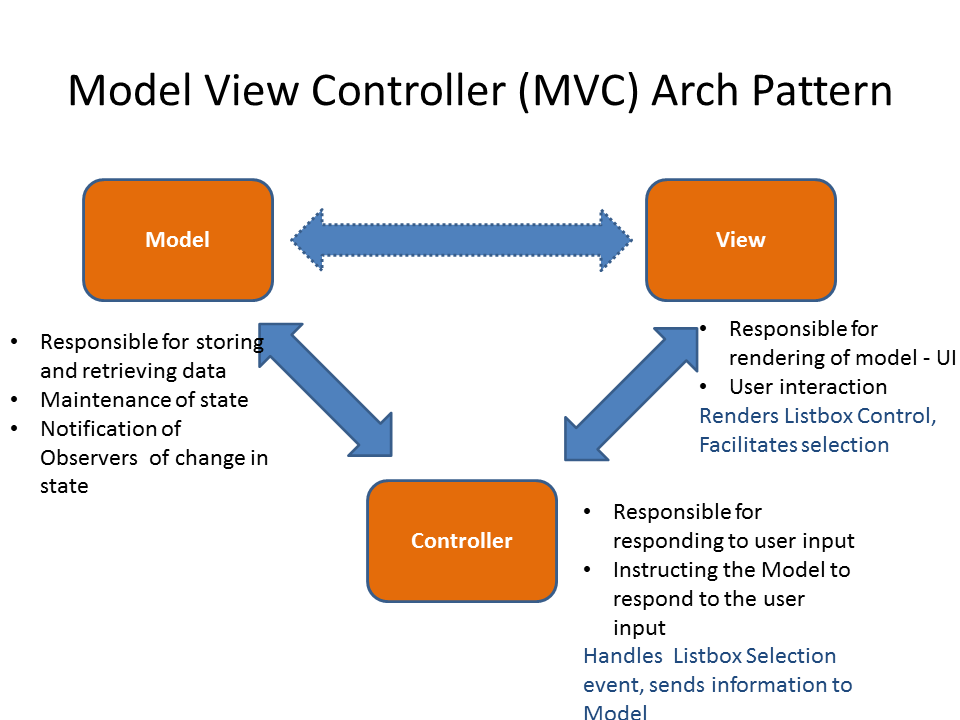
See more in MVC Model View Controller org file.
the web based MVC is different than the classic model due to request/response nature of the web.
- Model
The model is the application's data structure and is responsible for managing the data, logic and rules of the application. This is the data that will be displayed and modified. In Python frameworks, this component is often represented by the classes used by an object-relational mapper.
It gets input from the controller.
- View
The view is the visual representation (the presentation) of the data. There can be multiple representations of the same data. This component’s job is to display the data of the model to the user. Typically this component is implemented via templates
- Controller
The controller is like the middleman between the model and view. It takes in user input and manipulates it to fit the format for the model or view. The controller reacts to user actions (like opening some specific URL), tells the model to modify the data if necessary, and tells the view code what to display,
The execution of the Model-View-Controller looks like this:
- The user provides input.
- The controller accepts the input and manipulates the data.
- The controller sends the manipulated data to the model.
- The model accepts the manipulated data, processes it, and sends the selected data (in the strictest forms of MVC, via the controller) to the view.
- The view accepts the selected data and displays it to the user.
- The user sees the updated data as a result of their input.
The
benefitof theModel-View-Controllerdesign pattern is that each componentcan be built in parallel. Since each component is abstracted, the onlyinformationeach component needsis the input and output interfacefor the other two components. Components don't need to know about the implementation within the other components. What's more, because each component is only dependent on the input it receives,components can bereusedas long as the other components provide the data according to the correct interface.In classic MVC pattern, the
view(via ui elements) sends messages to thecontroller. thecontrollerthan updates themodelvia business logic. the model in turn fires change events that the view receives, and uses them update its display. this is really popular where the UI runs on a separate thread. see OS/X and IOS applications which use the builtin MVC pattern.in the
web based MVC, the view does a form get/post to acontroller. thecontroller updates state info, and builds anew view model. the view model is sent to the view engine, andreturns the view as htmlto the browser, which redisplay the page.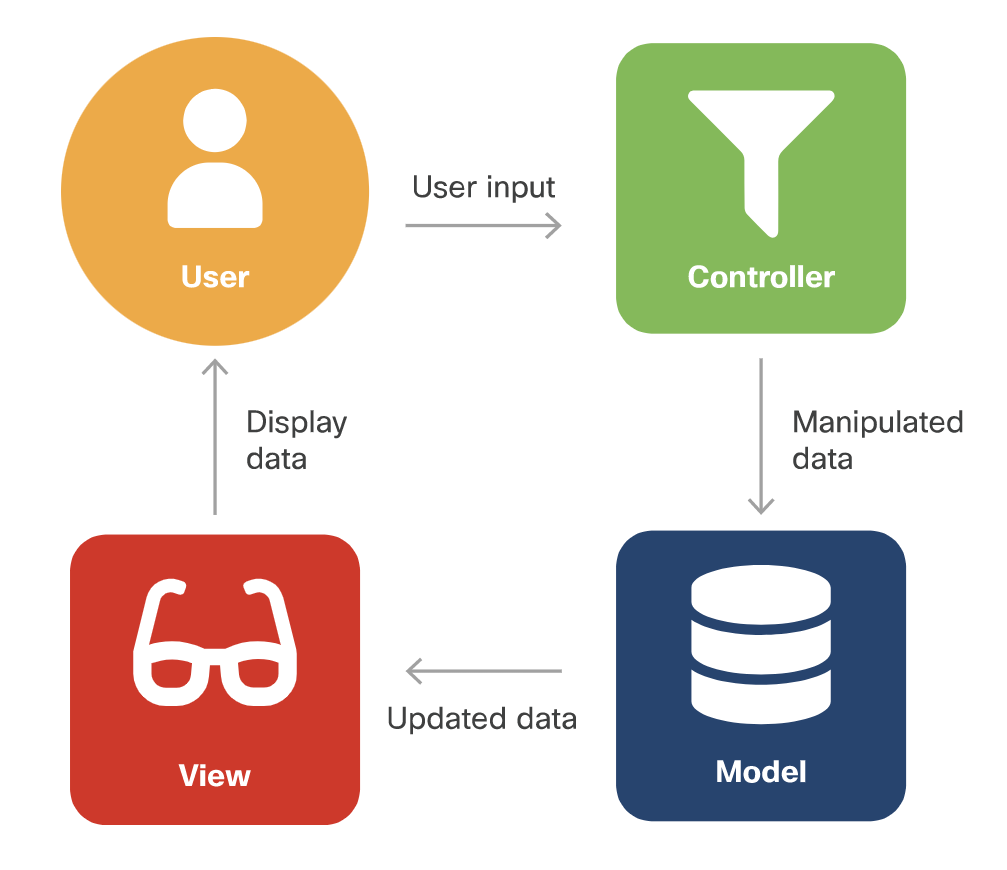
Figure 7: Model View Controller Cisco's diagram
4.2.2 MVC Benefits
Fasterdevelopment- Easy to provide
multiple views(no need to alter model or controller) - support
async(sofastfor user) - Mods
do NOT affectentire modelso getflexible presentation changes - Model returns data
without formatting Separationof concernindependent testingof componentspluggablecomponents
4.2.3 MVC Drawbacks
- increased complexity (even on small changes to model, you need to go through the controller to change the views)
- Excessive # of change notifications
- View and Controller tight coupling
- Separate controller sometimes needed.
4.2.4 MVC design patterns:
Common design pattersn that are used in MVC:
- Observer Pattern
- Strategy Pattern
- Composite Pattern
- Factory Patter
- Adapter Patter
This doc covers only the Observer Pattern
4.3 Observer Pattern (an MVC pattern)
Also known as Event-Subscriber or Listener pattern.
The Observer design pattern is based on subscriptions and notifications. It
allows observers (objects or subscribers) to track state changes of many
objects. Lets them receive events when there are changes to a object that
is being observed.
From wikipedia: "The observer pattern is a software design pattern in which an object, a.k.a. the subject:
- subjects maintains a list of its
dependentscalledobservers, - subjects have methods to
addandremoveobservers - implement a callback that
notifiesthemautomaticallyof any state changes,
usually by calling one of their methods."
The Observer pattern addresses the following problems:[2]
- A
one-to-manydependency between objects should be defined without making the objects tightly coupled. - It should be ensured that
when one object changes state, an open-ended number ofdependent objectsareupdated automatically. - It should be possible that
one objectcan notify anopen-ended number ofother objects.
Pattern is similar to a "publish-subscribe" pattern but there is a third component, the message broker, that is needed for them to communicate.
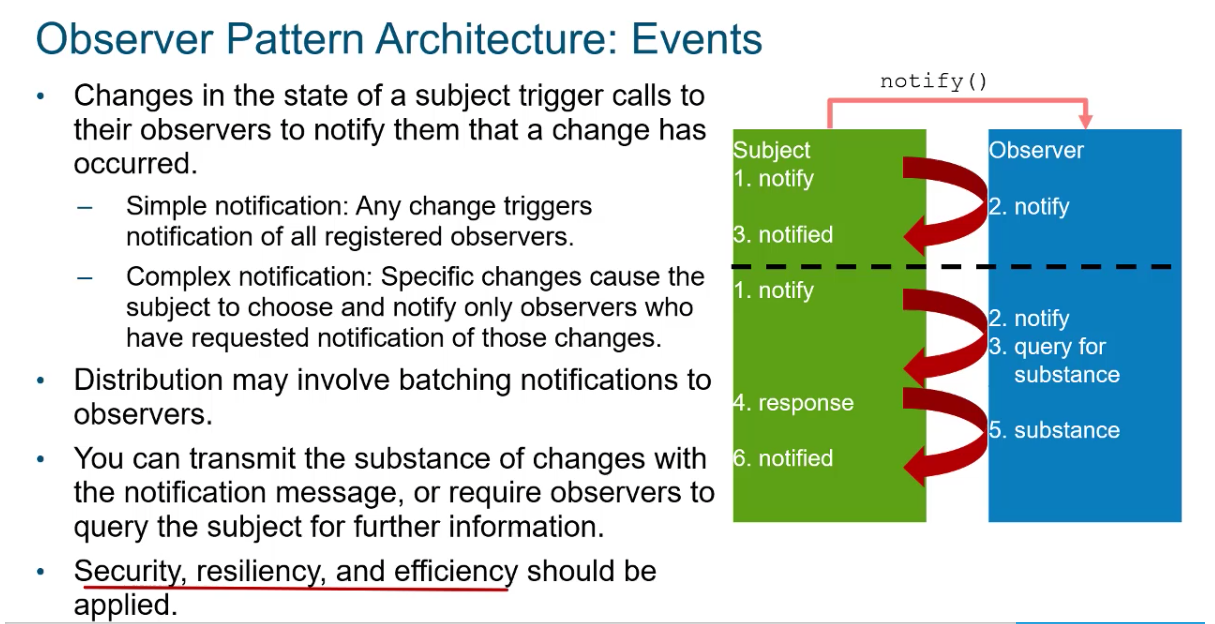
Uses notify() when subject
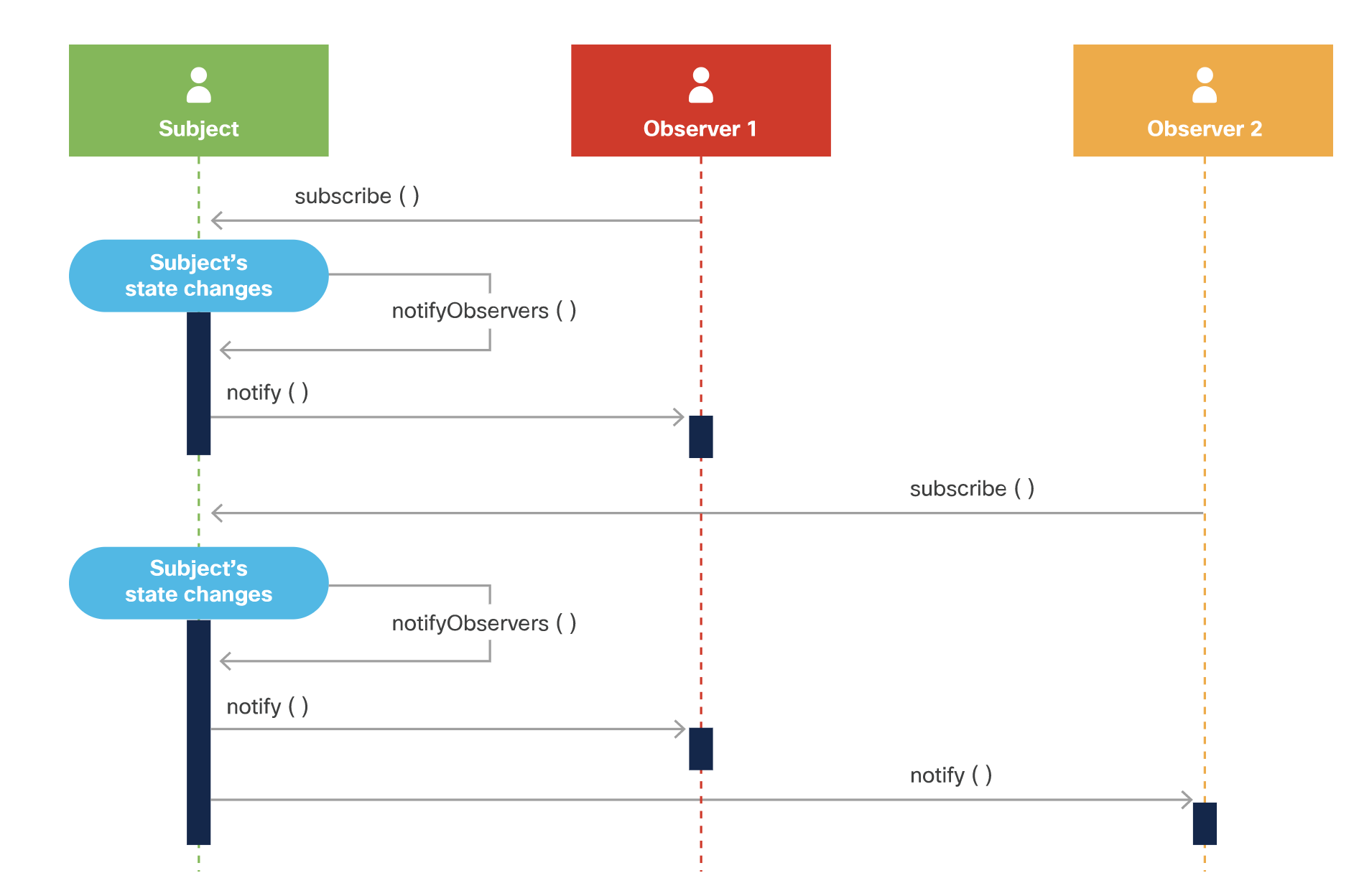
Executing this diagram would take these steps: The execution of this design pattern looks like this:
- An
observeraddsitselfto the subject'slist of observersby invoking the subject's method to add an observer. - When there is a
change to the subject,thesubject notifiesall of theobserverson the list by invokingeachobserver's callbackand passing in the necessary data. - The observer's callback is triggered, and therefore executed, to processh t~he notification.~
- Steps 2 and 3 continue
when the subject changes, i.e. there is an event - When the observer is done receiving notifications, it removes itself from the subject's list of observers by invoking the subject's method to remove an observer.
- they know about each other!
4.3.1 Observer registration
There needs to be a method of observers to register to a subject. This will most likely include a need to authenticate the observer.
4.3.2 Observer Benefits
- A benefit is that
observers get real time datafrom the subject as soon as subject changes. This is going to providebetter performance than polling - Support
loose couplingbetween objects that interact.- allows sending data to other classes without needing to change those other classes.
Flexible(observers can be added or removed at any time)
4.4 Comparing MTV with MVC
Model maps to Model : i.e. the data Template maps to View : i.e. the layout View maps to Controller : i.e. the business logic
| MVC | MTV | |
|---|---|---|
| Model | Model | the data |
| View | Template | the layout |
| Controller | View | the business logic |
4.5 1.7 Explain the advantages of version control
- collaboration
- backups / versions
- documented changes
4.6 1.8 Utilize common version control operations with Git
git sees a project directory as a root of a tree, with sub-directories as
trees, and files as blobs.
1.8.a Clone
git clone <url>
Takes the whole repository and copies it into a new directory. The repository
could be a remote one or a local one. If local it will just create hard-links
to the files in the repository, rather than duplicate space. (if you are
taking a backup, you can add option -no hard-links and the copies will be
true copies.
1.8.b Add/remove
git add <new or modified files> to the respository (from the staging area)
1.8.c Commit
git commit -m "Commit message"
takes staging area files and creates a point in time state of all the files
in the staging area (that your are adding)
1.8.d Push / pull
The git pull command is used to fetch i.e. download, content from a remote
repository and immediately update the local repository to match that content.
The git pull command is actually a combination of two other commands, git
fetch followed by git merge. In the first stage of operation git pull will
execute a git fetch scoped to the local branch that HEAD is pointed at. Once
the content is downloaded, git pull will enter a merge workflow. A new merge
commit will be-created and HEAD updated to point at the new commit.
git push # will send the locally modified files to the git repository
git pull # will receive a copy of the latest version from the git repository
1.8.e Branch
git branch will display all the available branches as well as the branch
currently active. git branch -vv will be extra verbose about it.
git branch covid-19 creates a new branch called covid-19, which points to
the same place where HEAD is pointing. At this point HEAD will point to
master as well as covid-19. (HEAD -> master, covid-19)
git checkout covid-19 will replace the current directory contents with the
contents of what covid-19 is pointing to, (which at this point is the same, so
no change really) but git log --all --graph --decorate shows us that we are
now (HEAD -> covid-19, master) ie. that HEAD is pointing to covid-19 which is
also the same place where master is.
Now if you start editing and adding files, the changes will be committed into the covid-19 branch, where HEAD is pointing. Master will still be pointing to the master snapshot.
any changes are committed to covid-19. i.e. (HEAD -> covid-19) and (master) is beside the snapshot it was on before. i.e. master stays the same
If we issue git checkout master, the current directory is overwritten with
what was in the master commit, and HEAD -> master, Covid-19 is unchanged.
So you can flip back and forth between two developments streams.
git checkout mastergit checkout covid-19
1.8.f Merge and handling conflicts
git merge is the opposite of git branch.
After you have 1 or more branches and you want to re-combine them into the
master train, you use the git merge.
git checkout master# to git you back on the master train.- git log –all –graph –decorate –oneline # just to take bearings
git merge covid-plotsIf there are no merge conflicts, you are done. However if conflicts arise between master and covid-plots, a human has to decide what changes take precedence and what changes will be discarded.git merge --abortif you get messed up.git mergetool# start comparing what changes over-write each other.- if you configure git properly, you can tell it to use
vimdiffevery time you run git mergetool. OR, you can manually runvimdiff - vimdiff
git merge --continueto proceed where you left off to make the human conflict resolution change.
1.8.g diff
git diff filename is the same as saying git diff HEAD filename i.e. it
compares the current file to the file as it was in the last commit.
Similarly git diff 42bcdea8 main.py will compare the current main.py file
to the state it was in the commit identifited by commit-id 42bcdea8
zp: checkout
gitcheckout -b <new branch name>
git checkout covid-19 will replace the current directory contents with the
contents of what covid-19 is pointing to, (which at this point is the same, so
no change really) but git log --all --graph --decorate shows us that we are
now (HEAD -> covid-19, master) ie. that HEAD is pointing to covid-19 which is
also the same place where master is.
5 Software Development Methods (agile, lean, and waterfall)
5.1 agile
Agile is flexible, and customer focused. Agile came about after years of
using waterfall and identifying its shortfalls. in 2001 developers wrote
the Manifesto for Agile Software Development, a.k.a. Agile Manifesto
5.1.1 Agile Manifesto
IndividualsandinteractionsoverprocessesandtoolsWorking softwareovercomprehensive documenationCustomer collaborationovercontract negotiationResponding to changeoverfollowing a plan
5.1.2 12 principles of Agile
Customer focus: Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.Embrace changeand adapt: Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage.Frequent delivery of working software: Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.Collaboration: Business people and developers must work together daily throughout the project.Motivated teams: Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job doneFace-to-face conversations: The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.Working software: Working software is the primary measure of progress.Work at a sustainable pace: Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain aconstant pace =indefinitely.Agile environment:Continuous attentiontotechnical excellenceandgooddesignenhances agility.Simplicity: Simplicity–the art of maximizing the amount of work not done–is essential.Self-organizing teams: The best architectures, requirements, and designs emerge from self-organizing teams.Continuous Improvement: At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
One of the differences between agile software development methods and
waterfall is the approach to quality and testing. In the waterfall model,
work moves through Software Development Lifecycle (SDLC) phases —with one
phase being completed before another can start —hence the testing phase is
separate and follows a build phase. In agile software development, however,
testing is completed in the same iteration as programming.
Because testing is done in every iteration—which develops a small piece of
the software— users can frequently use those new pieces of software and
validate the value. After the users know the real value of the updated piece
of software, they can make better decisions about the software's
future. Having a value retrospective and software re-planning session in each
iteration— Scrum typically has iterations of just two weeks—helps the team
continuously adapt its plans so as to maximize the value it delivers.
5.1.3 Agile variations
Agile Scrumsmall teams meet daily for short periods and work interactively in short sprintsLeaneliminate wasted effort in planning and execution. Reduce programmer cognitive loadXPExtreme Programmingas opposed toscrumxp is specific and prescriptive in coding practices
In all agile methodologies, many quick/small sprints are done versus the
single long waterfall marathon. In sprints, programmers tackle single tasks
a.k.a. stories as they think they can finish in a set time limit.
Product manager keeps track of the backlog of stories.
When a feature is at or near the top of the backlog, it gets broken down
into individual tasks a.k.a. user stories Each story should be small
enough that it can be comleted by the team in a single sprint. At the end
of each sprint, working software must be delivered.
Example of a user story:
As a auditor, I would like to see project id related to each expense itemso that we have full transparency and accountability of expenses- "As a <role> I would like <action>, so that <value|benefit>."
- Scrum teams
Made up of different roles, cross functional, collaborative, self-empowered Whole team is accountable for completion of a user story, even if an individual has comleted their individual task.
Less than 10 people
Scrum meets in a
stand-upwhich only lasts 10 minutes (hence you don't even need to sit down)Scrum masterruns thestand-upswhere each member states- what they have accomplished since last stand-up
- what they will work on for next stand-up.
Scrum masterreports on, and helps knock down obstacles.
5.1.4 Advantages of Agile
- The rapid and continuous delivery of software releases helps customers to better understand what the final piece will look like. This capability also provides a fully working code improved week after week, leading to customer satisfaction.
- Thanks to Scrum, people interaction is emphasized.
- Late project changes are more welcome.
5.1.5 Disadvantages of Agile
- This kind of approach lacks emphasis on good documentation, because the main goal is to release new code quickly and frequently.
- Without a complete requirement-gathering phase at the beginning of the process, customer expectations may be unclear, and there is a good chance for scope creep.
- Rapid development increases the chance for major design changes in the upcoming sprints, because not all the details are known.
5.2 lean automotive industry (history)
In Japan automotive industry, they pioneer lean management philosophy. The
aim is to eliminate waste. If you do not need it, get rid of it.
So minimize constraints (resources) so you are not overallocating resources
and creating waste.
- Purpose Which customer problems will we solve? The 5 "whys" are:
- why does it solve the problem?
- why continuously to fully understand the purpose
and keep going with more Why questions to get more answers. Actually,
who what where when whynot why why why why why - Process how will the org asses each major value stream to make sure it is
- valuable
- capable
- available
- adequate
- flexible
- People The root of it is getting the right people to take responsibility and produce outcomes.
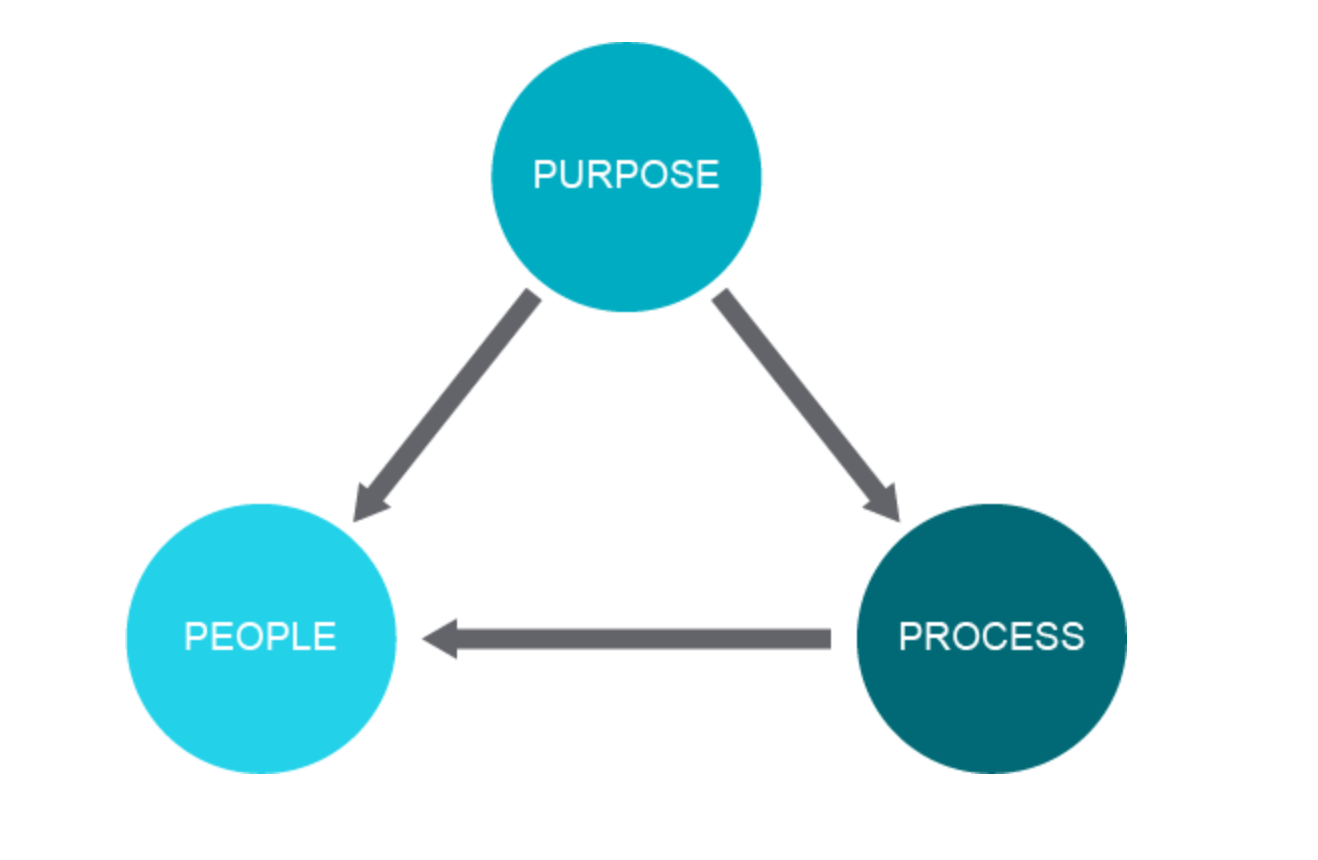
5.3 Lean 7 Principles (seven in total)
Eliminate wasteLean philosophy regards everythingnot adding value to the customeras waste (muda). Such waste may include:- Partially done work
- Extra processes
- Extra features
- Task switching
- Waiting
- Motion
- Defects
- Partially Done Work
Wasteful because it doesn't add value to the customer, and the time spent could have been spent on something that DOES add value to customer. The work probably won't be maintained either so eventually it becomes obsolete.
- Extra processes
Like a bunch of paperwork. Mostly they are useless and unneccessary. So obviously wasteful in time and effort and don't add value to the customer.
- Extra Features
If the customer did not ask for it, it probably does not add value to them. The customer won't use it, so it becomes obsolete.
- Task switching
Wastes a resources time, so don't assign a person to multiple projects. Same goes for other resources. It takes time for a person to switch over thinking and remembering where they left off on an interrupted task.
- Waiting
Waiting by definition is a waste of time. Waiting comes from:
- starting the project
- getting the right resources (staff)
- getting the requirements from the customer
- approvals of documentation
- getting answers
- making decisions
- implementation
- testing
- Motion
Motion of people is "when people need to physically walk from their desk to another team member to ask a question, collaborate etc. The waste is in the travel time, as well as the task-switching time.
Motion of artifacts is when documents or code are moved from one person to another. The artifact most likely is missing parts which means someone has to gather facts again, or the task swithing is done twice, which wastes time.
- Defects
Unnoticed defects (bugs) can cause a snowball effect wtih other features, so the time to debug is a waste. For a customer, running into a bug does not bring value, and wastes everyone's time.
Amplify learningSoftware development is a continuous learning process based oniterationswhen writing code. The learning process is sped up by usage of short iteration cycles – each one coupled withrefactoring and integrationtesting. Increasing feedback viashort feedback sessions with customershelps when determining the current phase of development and adjusting efforts for future improvements. During those short sessions, both customer representatives and the development team learn more about the domain problem and figure out possible solutions for further development. Thus the customers better understand their needs, based on the existing result of development efforts, and the developers learn how to bettersatisfy those needsexactly rather thanwaste time on featuresthatdo not bring value.Decide as late as possibleAs software development is always associated with some uncertainty, better results should be achieved with a set-based or options-based approach, delaying decisions as much as possible until they can be madebased onfactsand not onuncertain assumptions and predictions. Also if a decision has not yet been made, you can bemore flexible.Deliver as fast as possibleThe sooner the end product is delivered without major defects, thesoonerfeedback can be received, and incorporated into thenext iteration. Theshorter the iterations, the better the learning and communication within the team. With speed, decisions can be delayed.- enables customers to provide feedback
- enables developpers to amplify learning
- gives customers the features they need now
- does not allow customers to change their mind
- Makes everyone make decisions faster
- produces less waste
Empower the teamTraditionally, managers tell workers how to do their own job. In a work-out technique,the roles are turned– themanagersare taught how tolisten to the developers, so they can explain better what actions might be taken, as well as provide suggestions for improvements. The lean approach follows the agile principle[7]"build projects around motivatedindividuals[…] and trust them to get the job done"[8], encouraging progress, catching errors, and removing impediments, but not micro-managing.Build integrity inConceptual integrity means thatthe system’s separate components work welltogether as a wholewith balance between flexibility, maintainability, efficiency, and responsiveness. This could be achieved by understanding the problem domain and solving it at the same time, not sequentially. The needed information is received in small batch pieces – not in one vast chunk - preferably by face-to-face communication and not any written documentation. Theinformation flow should be constant in both directions– from customer to developers and back, thus avoiding the large stressful amount of information after long development in isolation.Optimize the whole"Think big, act small, fail fast; learn rapidly"[9] – these slogans summarize the importance of understanding the field and the suitability of implementing lean principles along the whole software development process. Only when all of the lean principles are implemented together, combined with strong "common sense" with respect to the working environment, is there a basis for success in software development.
5.4 waterfall
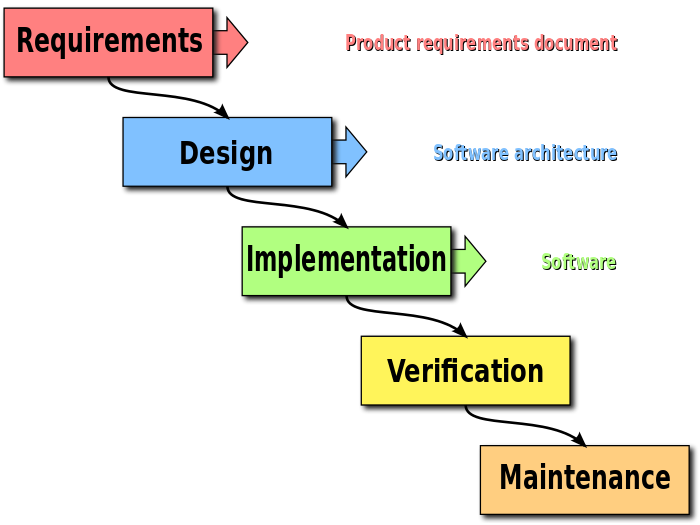
The waterfall model is a breakdown of project activities into linear
sequential phases, where each phase depends on the deliverables of the
previous one and corresponds to a specialisation of tasks. The approach is
typical for certain areas of engineering design. In software development, it
tends to be among the less iterative and flexible approaches, as progress
flows in largely one direction ("downwards" like a waterfall) through the
phases of conception, initiation, analysis, design, construction, testing,
deployment and maintenance.
One of the differences between agile software development methods and
waterfall is the approach to quality and testing. In the waterfall model,
work moves through Software Development Lifecycle (SDLC) phases —with one
phase being completed before another can start—hence the testing phase is
separate and follows only after the build phase. Also with waterfall, the
detailed requirements analysis up-front is supposed to lay out the details
of all the requirements that will be needed up front, so head-count and
timelines can be allocated. It rarely works out like this though, and since
there is no flexibilty to return to a completed phase it is very inflexible.
(In agile software development, however, testing is completed in the same
iteration as programming.)
- 1 Requirements and Analysis
owner and developer team gather the requirements for the s/w to be built. Important to include potential customer direct user's input.
- who are the stakeholders?
- what are their challenges/pain-points
- what has already been tried
- will this s/w replace existing s/w or processes?
- what is the culture/acceptance to change, risk, technical skills.
Next with these questions answered, start answering more settings questions:
- What is the company' current infrastructure, apps, user environments, i.e. windows or mac or linux users?, mobile or desktop, on-staff developer skills
- what is the company's current IT infrastructure, roadmap, headcount, developer skills,
- how much cloud? - mobile? web, devops, testing, ci/cd?
Then you start getting detailed requirements:
- what features are needed/wanted
- how many users will use it, at what projected load?
- what user experience is expected? mobile/web/desktop?
- what are the integration points to other s/w and company processes?
- how much should the s/w scale?
Finally start nailing down architecture:
- is the project feasible with the given budget
- how will the s/w be tested?
- how is this s/w delivered to end users?
Result is
SRSor Software Requirements Specification document. Compare that to agile dev. where you get an "MVP" minimum viable product, which is a starting point which will be used - Design
Takes the SRS as input. s/w is written to meet the SRS. Protypes are written, sometimes to confirm best design for the final s/w.
At conclusion of design phase output is a HLD (High-Level Design) and a LLD (Low-Level Design) document. HLD is written in plain english, LLD describes details in individual components, inter-component protocols, lists required classes etc.
Compare to
agilethat not document much at this stage. - Implementation.
Takes HLD/LLD as input and writes the code to completion. All components are written to completion. This is the longest phase. testing engineers also write test plans now.
Compare to
agilewhere some whiteboarding is enough to start coding. That works because the MVP is simple and team is small. Comparing further,agilebegins stressing code with tests much earlier. AndTDDwrites testbefore all else.Implementation phase a.k.a. build phase, coding phase, development phase.
- Testing
code is run through test plan. Test plan is a document that includes a list of every single test to be performed in order to cover all of the features and functionality of the software, as specified by the customer requirements.
Testing also includes:
- integration testing
- performance testing
- security testing
After testing phase is complete, code is ready for production.
- Deployment
Code is
moved into production. If no problems installing into production environement product manager with architects adn testing engineers decide whether to release the code. Code is ideally bug free, but ideals are never attained. - Maintenance
During
maintenance phaseyou- provide customer support
- fix bugs found in production
- work on s/w improvements
- gather new requirements/feature requests from customer
With new requirements collected the whole process loops back to start over. Compare that with
agilewhere this loop is closed immediately and often. Much shorter develpment sprints are the norm.
5.4.1 Benefits of Waterfall
Design errorsare highlightedbeforeanycode is written,saving time during the implementationphase.Good documentationis mandatory for this kind of methodology. This effort is useful for engineers in the later stages of the process.- Because the process is rigid and structured, it is
easy to measure progress and set milestones.
5.4.2 Disadvantages of Waterfall
- In the very early stages of a project, it can be
difficult to gather all the possible requirements. Clients can only fully appreciate what is needed when the application is delivered. - It becomes very difficult (and
expensive)to re-engineerthe application, making this approach veryinflexible. - The product will only be
shippedat the very end of the chain,without any middle phases to test. Therefore, it can be a verylengthyprocess.
6 Test-Driven Development, TDD
Start wtih capturing design requirements as tests, then writing software to
pass those tests. This is called Test-Driven Development (TDD).
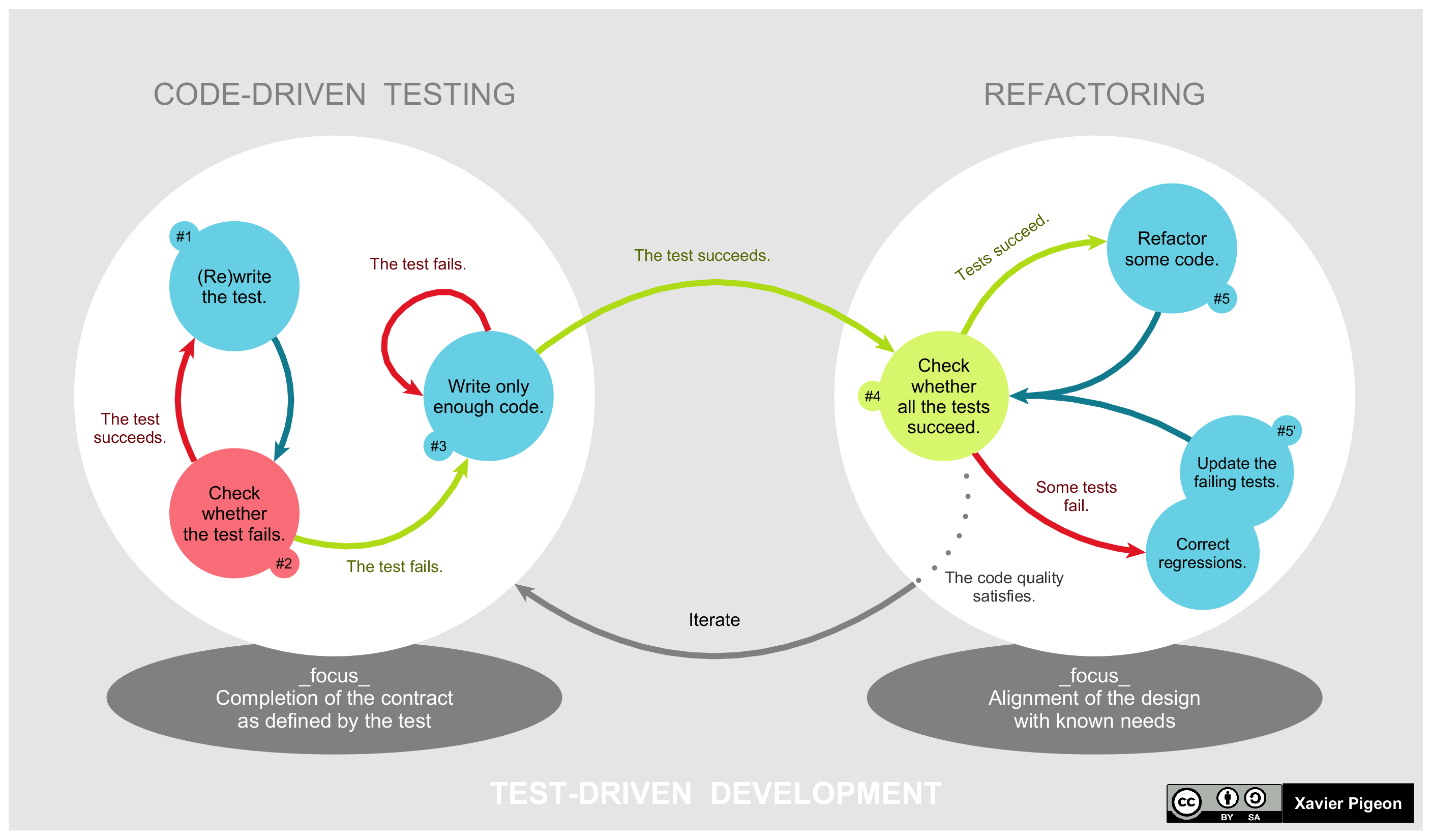
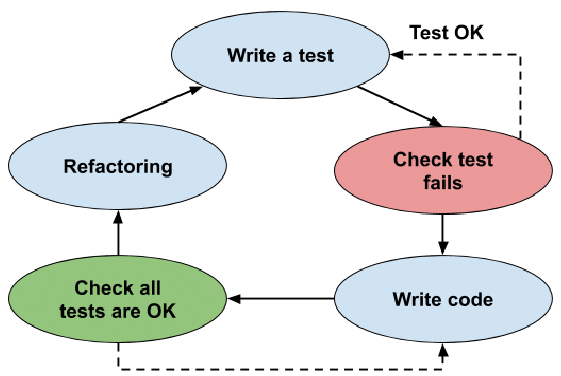
6.0.1 TDD Workflow
Workflow is as straightforward as the illustration below shows. In planning, the team thinks, discusses, and comes up with ideas. The ideas become tests, but the first test is designed to be expected to fail. The code is then rewritten to enable the test to pass. Once the test has passed, the code is refactored further until the best design eventually emerges. This newly refactored code continues to be under test until design finalization.

A differentiating feature of test-driven development versus writing unit tests
after the code is written is that it makes the developer focus on the requirements
before writing the code, a subtle but important difference.
From: mokacoding.com :
When learning about test driven development you'll soon come across the "red,
green, refactor" mantra. It's TDD in a nutshell. Write a failing test, write
the code to make it pass, make the code better.
The refactor set is often skipped though. People write the failing test, they
write the code to make it pass, and move on to the next test.
Skipping the refactor step means you're not taking full advantage of what the
TDD process has to offer. Having green lets you change your code with
confidence. Don't pass on this opportunity.
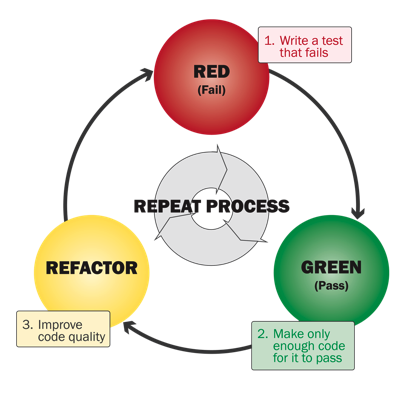
A more full view would be this lifecycle:
6.1 TD Functional Writing
Before you implement a function, focust on concrete examples of how the function should behave, as if it were already implemented.
Ask things like:
- "What are some
usualarguments? Things I expect to be sent to the function These are calleduse cases. - "What are some valid, but
unusualarguments? I might not expect to get these, but they are still valid arguments These are callededge cases - "What is some bone-head user, or nefarious hacker going to try with my funciton"
These are called
look this up
Finally ask "What is your expected return value for each set of inputs. These will be what your tests will assert against.
6.2 TDD from study group
Straight copy from /Test Driven Development Test-Driven Development Building small, simple unit and integration tests around small bits of code helps us:
Ensure that units are fit for purpose. In other words, we make sure that they're doing what requirements dictate, within the context of our evolving solution. Catch bugs locally (such as at the unit level) and fix them early, saving trouble later on when testing or using higher-order parts of our solution that depend on these components. The first of these activities is as important as the second (maybe more important), because it lets testing validate system design or — failing that — to guide local refactoring, broader redesign, or renegotiation of requirements.
Testing to validate (or initially, to clarify) design intention in light of requirements implies that we should write testing code before we write application code. Having expressed requirements in our testing code, we can then write application code until tests pass.
This is the principle of Test-Driven Development (sometimes called Test-First Development). The basic pattern of TDD is a five-step, repeating process:
- Create a new test (adding it to existing tests, if they already exist): The idea
here is to capture some requirement of the (perhaps not-yet-created) unit of application code we want to produce.
- Run tests to see if any fail for
unexpected reasons: If this happens, correct the tests. Note that expected failures, here, are acceptable (for example, if our new test fails because the function it's designed to test doesn't yet exist, that's an acceptable failure at this point).
- Write application code to pass the new test: The rule here is
to add nothing more to the application besides what is required to pass the test.
- Run tests to see if any fail: If they do, correct the application code
and try again.
- Refactor and improve application code: Each time you do, re-run
the tests and correcting application code if you encounter any failures.
By proceeding this way, the test harness leads and grows in lockstep with your application, perhaps literally on a line-by-line basis, providing very high test coverage (verging on 100%) and high assurance that both the test harness and the application are correct at any given stopping-point. Co-evolving test and application code this way:
Obliges developers to consistently think about requirements (and how to capture them in tests). Helps clarify and constrain what code needs to do (because it just has to pass tests), speeding development and encouraging simplicity and good use of design patterns. Mandates creation of highly-testable code. This is code that, for example, breaks operations down into pure functions (functions that don't access global variables of possibly-indeterminate state) that can be tested in isolation, in any order, and so on.
6.3 1.1 Compare data formats (XML, JSON, and YAML)
See my org file on XML <key> value </key> and JSON "Key":Value and YAML Key:Value
6.4 1.2 Describe parsing of common data format (XML, JSON, and YAML) to Python data structures
- minidom for XML
from xml.dom.minidom import parse, parseString datasource = open('c:\\temp\\mydata.xml') dom2 = parse(datasource) - xml.etree.ElementTree
import xml.etree.ElementTree as ET tree = ET.parse('acme-employees.xml') tree2 = ET.fromstring(acme-employees-long-string-of-xml) # if a stringET has two classes,
ElementTreeclass represents thewhole xmldocument as a tree. WhileElementrepresentsa single nodein this tree. So interactions to the whole document use ElementTree while single elements and its sub-elements use Element.Could also use xmltodict
- json:
Read (json.load) and write (json.dump)
with open('/Users/zintis/eg/code-examples/mydevices.json', 'r') as readdevices: ingest_dict = json.load(readdevices) with open('/Users/zintis/eg/code-examples/sample.json', 'w') as dumpback2json: json.dump(ingest_dict, dumpback2json) - json.load(filehandle) to read
- json.dump(jsonobject, filehandle) to write
A real-life example of an ip table read in from a router. The file is [file:///Users/zintis/eg/code-examples/show-ip-route-response.json]
After the json is parsed into a python dictionary, say X, then 172.16.17.18 could be retrieved as:
IPaddr = X["ietf-interfaces"]- YAML
writing:
with open(r'E:\data\store_file.yaml', 'w') as file: documents = yaml.dump(dict_file, file)
You can also dump in a sorted keys order:
with open(r'E:\data\store_file.yaml') as file: documents = yaml.load(file, Loader=yaml.FullLoader) sort_file = yaml.dump(doc, sort_keys=True) print(sort_file)
7 Full section on python interfaces, coupling, etc
7.1 Cohesion
Defined as code that is performing to a single task or tight, narrow range of
tasks. You want high cohesion. If a function is doing two unrelated things,
it has low cohesion. bad
Same is exteded from functions, up to modules. So you want modules that
contain strongly related classes and functions.
7.2 Coupling
Loose Coupling in s/w development means reducing dependencies of a module
class or function that uses different modules, classes or finctions directly.
Ideally you want to reduce dependencies between modules so loose coupling so
that you can make changes to one module, and not affect other modules.
Note: I did not write the following section. source unknown though. My apologies to the author. TODO: find the author and add the credit.
In dynamically typed languages, no explicit interface is defined. In these types of languages, you would normally use duck typing, which means that the appropriateness of an object is not determined by its type (like in the statically typed languages) but rather by the presence of properties and methods. The name "duck typing" comes from the saying, "If it walks like a duck and it quacks like a duck, then it must be a duck." In other words, an object can be used in any context, until it is used in an unsupported way. Interfaces are defined implicitly with adding new methods and properties to the modules or classes.
Observe the following example of the app.py module.
import db class App: def __init__(self): self.running = False self.database = db.DB() def startProgram(self): print('Starting the app...') self.database.setupDB() self.running = True def runTest(self, DB): print('Checking if app is ready') if 'Users' in DB.keys(): return True else: return False The signature of db.py is as follows: from init import Initialization class DB: def __init__(self): self.DB = None def setupDB(self): print('Creating database...') self.DB = {} init = Initialization() self.DB = init.loadData(DB) The initialization class is part of the init module. import app initData = { 'Users': [ {'name': 'Jon', 'title': 'Manager'}, {'name': 'Jamie', 'title': 'SRE'} ] } class Initialization: def __init__(self): self.data = initData self.application = app.App() def loadData(self, DB): print(self.data) DB = self.data validate = self.application.runTest(DB) if validate: return DB else: raise Exception('Data not loaded')
This is an example of a cyclic dependency where the app module uses the database module for setting up the database, and the database module uses the init module for initializing database data. In return, the init module calls the app module runTest() method that checks if the app can run.
In theory, you need to decide in which direction you want the dependency to progress. The heuristic is that frequently changing, unstable modules can depend on modules that do not change frequently and are as such more stable, but they should not depend on each other in the other direction. This is the so-called Stable-Dependencies Principle.
Observe how you can, in a simple way, break the cyclic dependency between these three modules by extracting another module, appropriately named validator.
class Validator: def runTest(self, DB): print('Checking if app is ready...') if 'Users' in DB.keys(): return True else: return False
The app class no longer implements the logic of the runTest() method, so the init module does not reference it anymore.
import validator # <... output omitted ...> class Initialization: def __init__(self): self.data = initData self.validator = validator.Validator() def loadData(self, DB): DB = self.data validate = self.validator.runTest(DB) if validate: return DB else: raise Exception('Data not loaded')
The cyclic dependency is now broken by splitting the logic into separate modules with a more stable interface, so that other modules can rely on using it.
Note Python supports explicit abstractions using the Abstract Base Class (ABC)
module, which allows you to develop abstraction methods that are closer to the
statically typed languages. Modules with stable interfaces are also more
plausible candidates for moving to separate code repositories, so they can be
reused in other applications. When developing a modular monolithic
application, it is not recommended to rush over and move modules in separate
repositories if you are not sure how stable the module interfaces
are. Microservices architecture pushes you to go into that direction, because
each microservice needs to be an independent entity and in its own
repository. Cyclic dependencies are harder to resolve in the case of
microservices.
7.2.1 Single-Responsibility Principle
A single module should be responsible to cover some intelligible and specific
technical or business feature. As said by Robert C. Martin, coauthor of the
Agile Manifesto, a class should have one single reason to change. That will
make it easier to understand where lay the code that needs to be changed when
a part of an application must be revisited. When a change request comes, it
should originate from a tightly coupled group of people, either from the
technical or business side, that will ask for a change of a single narrowly
defined service. It should not happen that a request from a technical group
causes an unwanted change in the way business logic works. When you develop
software modules, group the things that change for the same reasons, and
separate those that change for different reasons. When this idea is followed,
the single-responsibility design principle is satisfied.
Modules, classes, and functions are tools that should reduce complexity of your application and increase reusability. Sometimes, there is a thin line between modular, readable code, and code that is getting too complex.
7.3 Loose Coupling
Loose coupling in software development vocabulary means reducing dependencies
of a module, class, or function that uses different modules, classes, or
functions directly. Loosely coupled systems tend to be easier to maintain and
more reusable.
The opposite of loose coupling is tight coupling, where all the objects mentioned are more dependent on one another.
Reducing the dependencies between components of a system results in reducing the risk that changes of one component will require you to change any other component. Tightly coupled software becomes difficult to maintain in projects with many lines of code.
In a loosely coupled system, the code that handled interaction with the user interface will not be dependent on code that handles remote API calls. You should be able to change user interface code without affecting the way remote calls are being made, and vice versa.
Your code will benefit from designing self-contained components that have a well-defined purpose. Changing a part of your code without having to worry that some other components will be broken is crucial in fast-growing projects. Changes are smaller and do not cause any ripple effect across the system, so the development and testing of such code is faster. Adding new features is easier because the interface, for interaction with the module, and implementation will be separated.
So how do you define if a module is loosely or tightly coupled?
Coupling criteria can be defined by three parameters:
Size Visibility Flexibility This criteria is based on the research of Steve McConnell, an author of many textbooks and articles on software development practices.
The number of relations between modules, classes, and functions defines the size criterion. Smaller objects are better because it takes less effort to connect to them from other modules. Generally speaking, functions and methods that take one parameter are more loosely coupled than functions that take 10. A loosely coupled function should not have more than two arguments; more than two should require justification. Functions that look similar, or they share some common code, should be avoided and alternated if they exist. A class with too many methods is not an example of loosely coupled code.
When you implement a new fancy solution to your problem, you should ask yourself if your code became less understandable by doing that. Your solutions should be obvious to other developers. You do not get extra points if you are hiding and passing data to functions in a complex way. Being undisguised and visible is better.
For your modules to be flexible, it should be straightforward to change the interface from one module to the other. Examine the following code:
import addressDb class Interface: def __init__(self, name, address): self.name = name self.address = address self.state = "Down" class Device: def __init__(self, hostname): self.hostname = hostname self.motd = None self.interface = Interface def add_to_address_list(self): addressDb.add(self.interface) # The device module interacts with the add() function of a module addressDb. def add(interface): <... implementation omitted ...> print(f'adding address {interface.address}') At first sight, this code looks good. There are no cyclic dependencies between the modules. There is actually just one dependency. The function takes one argument and there is no data hiding or global data modification, so it looks pretty good. What about flexibility? What if you have another class called "Routes" that also wants to add addresses to the database, but it does not use the same concept of interfaces? The addressDb module expects to get an interface object from where it can read the address. You cannot use the same function for the new Routes class; therefore, the rigidness of the add() function is making code that is tightly coupled. Try to solve this using the next approach. def add(address): <... implementation omitted ...> print(f'adding address {address}') The add() function now expects an address string that can be stored directly without traversing the object first. The function is not tied anymore to the interface object; it is the responsibility of the caller to send the appropriate value to the function. class Device: def add_to_address_list(self): addressDb.add(self.interface.address)
Note Python, which uses duck typing, did not require the exact object of type interface, but only an object that can conform with the add() function. In statically typed languages, the correct object type would be required. If you fundamentally change the conditions of a function in a loosely coupled system, no more than one module should be affected.
The easier a module or function can call another module or function, the less tightly coupled it is, which is good for the flexibility and maintenance of your program code.
Cohesion
Cohesion is usually discussed together with loose coupling. It interprets classes, modules, and functions and defines if all of them aim for the same goal. The purpose of a class or module should be focused on one thing and not too broad in its actions. Modules that contain strongly related classes and functions can be considered to have strong or high cohesion.
The goal is to make cohesion as strong as possible. Aiming at strong cohesion, your code should become less complex, because the logically separated code blocks will have a clearly defined purpose. This should make it easier for developers to remember the functionality and intent of the code.
def save_and_notify(device, users): filename = '/opt/var/' file = open(f'{filename}', "w") file.write(device.show()) file.close for user in users: sendEmail(user)
The saveandnotify() function is an example of low cohesion, because even the name suggests that the code in the function performs more than one action; it backs up the data and notifies the users.
Note Do not rely on a function name to identify if it has high or low cohesion. A function should focus on doing one thing well. When a function executes a single thing, it is considered a strong, functional cohesion as described by McConnell.
Here is an example of a code with lower cohesion:
def log(logdata): file = open('/var/logs/app.log}', "w") file.write(logdata) file.close() logdata = [] return logdata
In the log() function, the collected logs in the logdata variable are first being logged to disk, and then the same data is cleared in the next step. This is an example of communicational cohesion, in which there are multiple operations that need to be performed in a specific order, and those steps operate on the same data. Instead, you should separate the operations into their own functions, in which the first logs the data, and the second—ideally, somewhere close to the definition of the variable—clears the data for future usage.
Another example is logical cohesion, which happens when there are multiple operations in the same function and the specific operation is selected by passing a control flag in the arguments of a function.
def actions(device, users, action): if action == 'backup': file = open(f'{filepath}', "w") file.write(device.show()) file.close if action == 'notify': for user in users: sendEmail(user) if action == 'wipe': device = None return device
Instead of relying on a flag inside a single function, it would be better to create three separate functions for these operations. If the task in a function would not be to implement the operations, but only to delegate commands based on a flag (event handler), then you would have stronger cohesion in your code.
8 Software Developement and Design
8.1 Microservices
Software development life cycle, SDLC, starts wtih an idea, ends with quality
working s/w. It includes:
(Not to be confused with Build-Test-Deploy steps in CI/CD processes. In fact
- Plan
- Code
BuildTestDeplooy- Operate
- Monitor
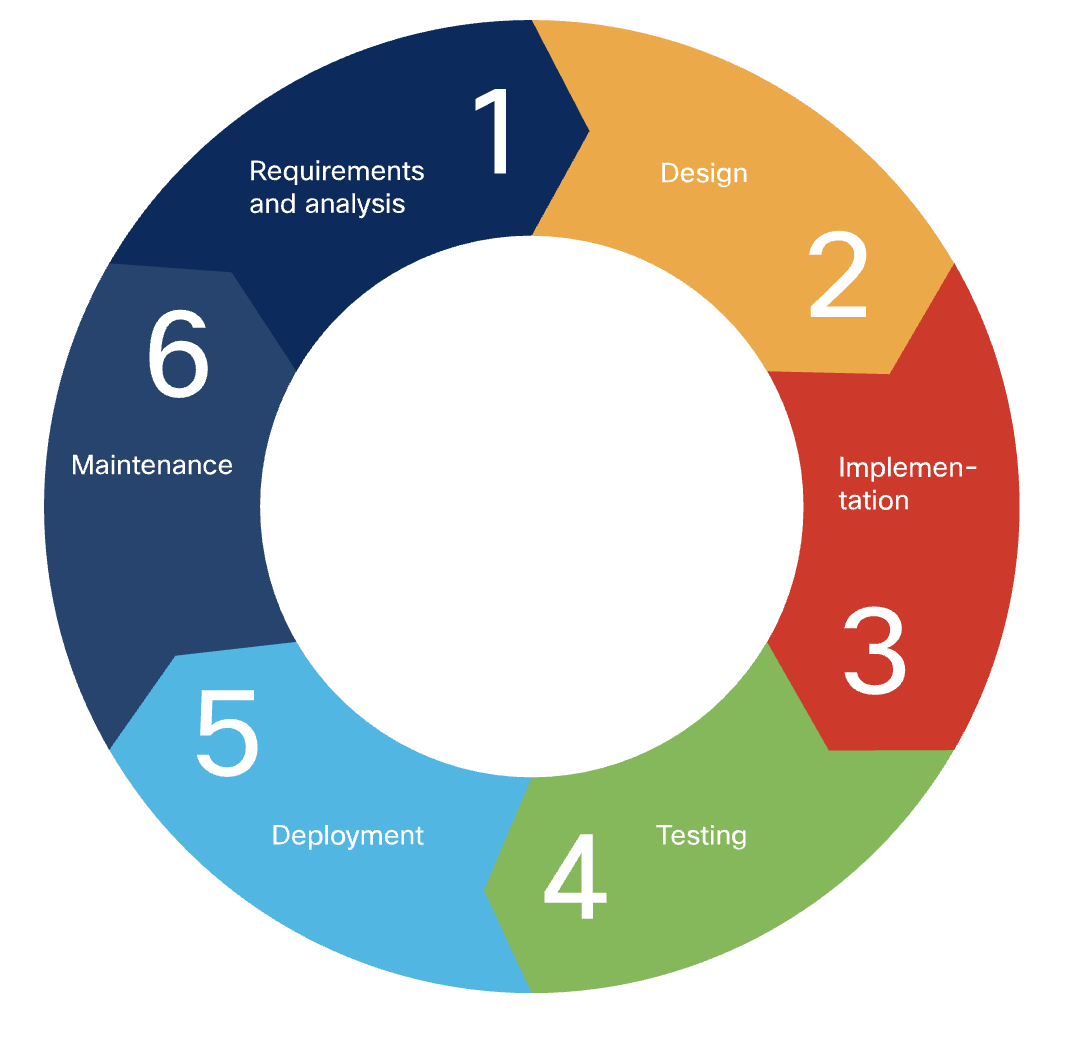
Several methodologies can be used for this purpose. Such as waterfall, agile,
test driven, lean
From the Cisco Study Group:
Cloud-based applications that are meant to be flexible and scalable,
supporting complexities that networks introduce, will use a different
approach to software design than, for example, an enterprise application that
can be more predictable, with a simpler deployment model. Different
architecture and design patterns emerge from the needs to make efficient use
of the deployment options and services that applications are offering.
Cloud-based and other applications are often split into a suite of multiple
smaller, independently running components or services, all complementing each
other to reach a common goal. Often, these applications communicate with
lightweight mechanisms such as a Representational State Transfer (REST)
application programming interface (API).
This type of architecture is widely known as microservices. With
microservices, each of the components can be managed separately. This means
that change cycles are not tightly coupled together, which enables developers
to introduce changes and deliver each component individually without the need
to rebuild and redeploy the entire system. Microservices also enable
independent scaling of parts of the system that require more resources,
instead of scaling the entire application. The following figure shows an
example of microservice architecture with multiple isolated services.
8.1.1 Monoliths
An applicsation that runs a single logical executable unit. If your app is simpler than writing a monolith may be the way to go.